









































Introduction
The potential of LLM Applications is remarkable, as they can develop software that understands and produces human-like text and engages in seamless and authentic conversations. These applications possess the ability to assist users across diverse domains with unparalleled efficiency.
LLMs have a profound impact on efficiency and productivity, representing a transformative solution in today’s information-rich and communication-driven world. With their remarkable ability to understand and produce human-like text, these models effectively bridge the gap between humans and machines, making interactions more intuitive and accessible.
One compelling reason for the need for LLMs is to automate complex tasks. Businesses can utilize LLM-powered applications to streamline content creation, customer support, and data analysis, reducing the burden of repetitive tasks on human resources. The implementation of LLMs results in a substantial reduction in both time and expenses and empowers organizations to assign their valuable human resources to more critical and innovative tasks.
Related read: The Top Most Useful Large Language Model Applications
In this article, we will discover the fundamentals of Language Models, delve into the technology stack required for development, discuss data collection and preprocessing, guide you through the model training process, and show you how to build a user-friendly interface for your application.
We will begin with understanding the basics of LLMs➡️
Understanding the Basics of Language Models
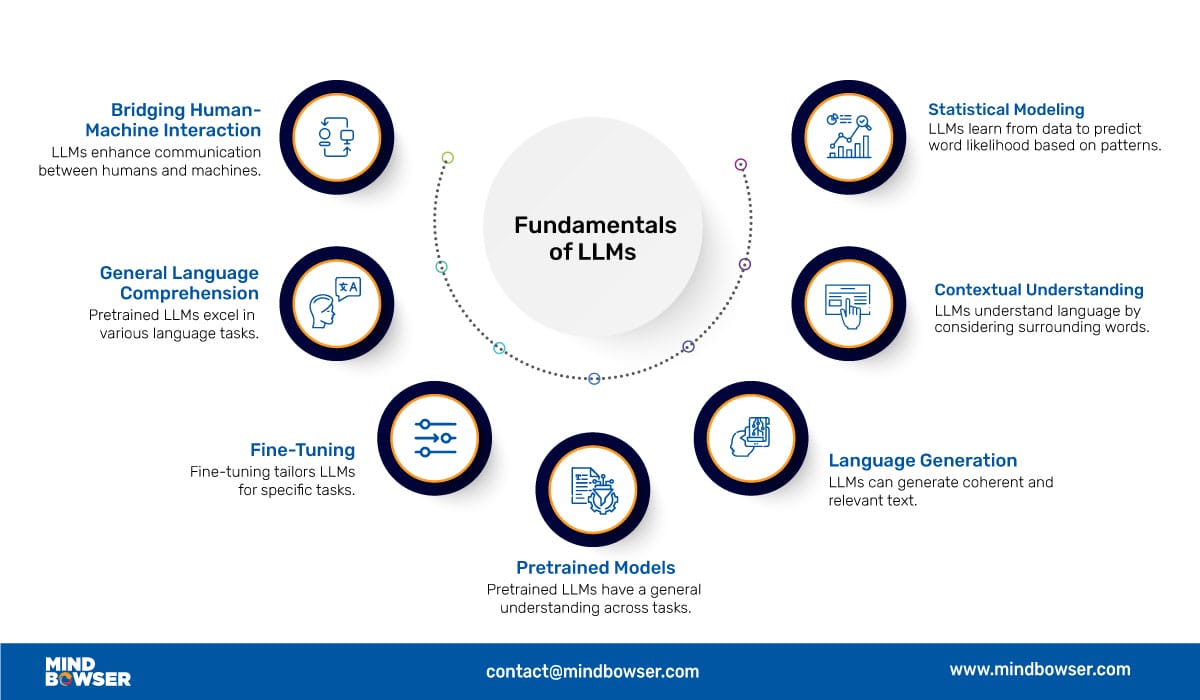 Fig: Fundamental of LLMs
Fig: Fundamental of LLMs
LLM Applications, serve as the fundamental aspects of modern AI-powered natural language understanding and generation systems. At its core, LLM is a statistical model tailored to assume the words or phrases occurring in a given context based on the words that precede them.
GPT-3, is one of the most popular LLMs in the current landscape. It represents efficiency in different areas, including text generation, language translation, sentiment analysis, and much more. GPT-3 possesses the ability to understand and produce text that resembles human language across diverse use cases. It has gained a position of preferred option for developers aiming to incorporate natural language understanding and generating into their LLM Applications.
Pretrained language models like GPT-3, including the LLM Application, possess efficiency in general language comprehension. However, to design these models for specific tasks or domains, the process of fine-tuning is employed. This entails training the model on a more focused dataset that pertains to the desired objective. Fine-tune plays a pivotal role in attaining optimal performance and enhancing the models of domain-specific language.
Related read: Large Language Models: Complete Guide for 2024
Selecting the Right Technology Stack
The process of determining the suitable technology stack is important in the development of LLM Applications. We have listed some key factors to consider while making the crucial decision of choosing the relevant technology stack for your LLM Application.
Choosing a Programming Language
🔸 Python
Python is widely recognized as the predominant language utilized for AI and natural language processing because of its extensive repertoire of libraries and frameworks. The language holds a position in LLM Application development, owing to the convenience offered by libraries such as TensorFlow, PyTorch, and Hugging Face’s Transformers, facilitating ease of use in working with language models.
🔸 JavaScript
JavaScript is an essential language for front-end development to build web-based applications or interactive chatbots. Additionally, you can utilize Node.js on the server side to facilitate JavaScript-based back-end development, thus maintaining a cohesive language across your entire tech stack.
Related read: Chatbot Platforms Are the Future of Marketing for Enterprises
🔸 Other Languages
While Python and JavaScript are the most widely used, other languages like Java and Ruby can also be used, depending on your project’s specific requirements and your team’s expertise.
Frameworks and Libraries for LLM Applications
🔸 Hugging Face Transformers
Hugging Face offers an extensive library and ecosystem that caters to the needs of developers working with transformers and LLM Applications. Their transformers library encompasses a wide range of pre-trained models, as well as tools for fine-tuning these models. It provides a user-friendly API that facilitates seamless integration into various applications.
🔸 LangChain
LangChain is a cutting-edge open-source framework designed specifically to develop applications using LLM Applications. Its comprehensive range of features simplifies the process of incorporating LLMs into applications, offering seamless API calling, efficient memory management, streamlined chaining capabilities, and a wide range of agents for seamless interactions with the LLMs.
Data Collection and Preprocessing
The process of collecting data for the development of LLM Applications entails collecting large amounts of data. The data plays an instrumental role in the model, allowing it to understand the syntax, semantics, and patterns within a language. The performance of the model is greatly influenced by the quality and variety of collected data, rendering this step an essential aspect of the development process.
Data cleaning is one of the most important steps in data preparation. It involves identifying and removing duplicates, correcting errors, and standardizing the formatting of the data. When dealing with text data, additional preprocessing techniques are often applied. These techniques include tokenization, stemming, and lemmatization.
While dealing with data collection and preprocessing, ensure that your data collection and processing comply with data privacy regulations such as GDPR, HIPAA, or CCPA. Protect user and sensitive information through encryption and access controls.
Training Your Language Model
The training phase of a language model is a crucial step that demands meticulous configuration and ongoing monitoring. Let’s understand how to set up the training environment, fine-tune a pre-trained Large Language Model (LLM), optimize hyperparameters, and effectively monitor the progress of your model.
Ready to Begin LLM App Development? Let's start! Hire Our Developers for Expert Guidance and Support
Setting Up the Training Environment
Depending on the scale of your project, teams should choose an appropriate hardware setup for their LLM Application. Training Large Language Models often benefits from powerful GPUs or TPUs to accelerate computation. Apart from the hardware, it is necessary to choose the right deep learning framework.
The framework chosen should support the model architecture of your LLM. For transformer-based models, hugging face transformers library, PyTorch, and TensorFlow are some suitable options. Moreover, it is necessary to install CUDA (Compute Unified Device Architecture) and cuDNN (CUDA Deep Neural Network library) to provide acceleration for GPUs.
Fine Tuning a Pre-Trained LLM
Fine-tuning a pre-trained LLM Application involves using a specific data set and adjusting the model’s architecture for a specific task. This can be done by adding task-specific layers or adjusting the existing ones. Pre-processing and formatting data according to the model’s requirement is also important. After loading the pre-trained LLM and using the required dataset it is possible to measure factors like accuracy and loss for further tuning of the LLM.
Hyperparameter Optimization
Hyperparameters refer to the external configurations that are to be set before the training process of the LLM Application begins. There are a few major hyperparameters to be optimized for better performance. These include parameters like the learning rate, batch size, epoch, and weight decay.
Techniques like grid searching and Bayesian optimization help in conducting extensive training and using computational resources efficiently. Hyperparametric optimization not only improves the efficiency of the model but also helps in reducing underfitting and overfitting.
Progress Monitoring of the LLM
Monitoring the progress of a Large Language Model is essential to understand how well the model is learning. It also helps in the identification of areas where adjustments are needed. Keeping track of metrics like training loss, validation loss, and accuracy helps in determining the progress level of the LLM Application.
Custom plots and graphs like the tensorboard for the tensorflow framework help in visualizing the progress of the LLM Application training. Apart from this, implementing techniques like early stopping, saving the best model, and periodic evaluation helps in diagnosing potential issues and taking corrective actions while training the LLM.
Building User Interfaces
Integrating Language Models (LLMs) with User Interfaces (UI) makes interactions between users and the LLM Application more effortless and engaging. The ability of pre-trained LLMs to understand and engage in conversations with the user is transforming the user engagement field of every application.
Developing a user interface for LLMs includes the prioritization of guiding the user efficiently and better error handling using continuous feedback. User Interfaces for LLMs should be designed in a way that showcases the capabilities of the model as well as provides an interactive user experience.
Related read: Basics Of UI/UX For Product Development
Backend Development
Backend Development for an LLM-based application involves the integration of the core backend of your application with Large Language Models. This is usually done with API integration as many LLMs are hosted as APIs. This helps in leveraging the entire capabilities of the language model.
However, this process of integrating the core backend of the application with Large Language Models demands pre-processing of data like cleaning, structuring, and tokenization before sending it to the language model. Once the input data is processed it is necessary to ensure the efficiency of response handling for the use of output data provided by the language model.
Considering the computational intensity of Large Language Models, the infrastructure of the backend should be designed in a way that can handle an increase in demand. While dealing with sensitive data, LLM-based applications should use secure communication protocols.
Moreover, using robust error handling along with reliable monitoring and logging ensures the resilience of the backend system of the LLM Application. These factors collectively form a strong foundation for the backend system that helps in leveraging the capabilities of LLM and enhances user experience and functionality.
Testing and Quality Assurance
Testing and Quality Assurance play an important role in the final stages of any LLM Application development. Thorough testing should be done using diverse inputs for the LLM to ensure reliable outputs. Manual, as well as an automated testing approach using potential real case scenarios, complex queries, and language style, should be implemented to test the understanding and generating capabilities of the LLM.
Using the data collected from the testing, proper rectification and adjustments should be performed to ensure the quality of the output generated by the application. Along with this, incorporating user-generated feedback into the testing process helps to refine the LLM’s performance using a practical approach.
Testing and Quality Assurance are important aspects in the development of an LLM-based application and ensure delivery of a user-friendly and performance-optimized robust application.
Deployment and Scaling
Once the LLM Application is developed and tested, deploying your work to make it available and accessible to users is a crucial task. Choosing the right deployment strategy that aligns with the goals and capabilities of application development as well as the infrastructure of the application is also important. For LLM-based applications deployment techniques like containerization using docker are used.
Serverless architectures and traditional cloud setups assist in automatic scaling and ensure a seamless deployment and also help in proper documentation which minimizes the risk of potential errors and disruptions.
LLMs being intense on the computation side, scaling is essential to handle an increase in user demand. This is done primarily through vertical and horizontal scaling. Vertical scaling involves the addition of hardware capabilities to an existing server. However, it is limited to the use of a single machine and hence cannot be scaled further once the server has reached the capability to process additional hardware.
On the other hand, horizontal scaling refers to the addition of more servers to reduce the processing and computation load. This cloud-based scaling approach is more dynamic and efficient as servers can be added or removed as per the demand. Some cloud-based providers also enable the option of auto-scaling which makes use of predefined conditions. This optimizes the use of resources maintaining smooth performance during stages of increased demand.
Monitoring and Maintenance
Monitoring and Maintenance are post-deployment tasks that will always be a part of ongoing operations for an LLM-based application. These crucial operations ensure optimum and continual performance, identification of potential problems, and also help in adapting to changing demands.
Monitoring the performance metrics using robust tools helps keep track of important data like time for response, error frequency, and utilization of resources. This in turn guides developers to make improvements, add features, and maintain the overall performance capabilities of the application.
Moreover, creating automated alerts for critical situations and conditions is also an important part of monitoring to identify risks before they affect the users. These alerts can be created using pre-existing metrics and result patterns.
Providing regular updates. Optimization of existing code, maintaining the database, performing security audits, and integrating the feedback generated by users are also some aspects to be considered during the maintenance process.
Ethical Considerations and Bias Mitigation
While training the LLM Application, the existence of a biased training module or data output is a potential factor. To avoid and overcome these biased results, it is necessary to perform a proper bias assessment. Along with this, a fine eye toward ethical considerations is also important for responsible LLM Application development. It is necessary to analyze data that can create biased model outputs for certain conditions.
To maintain transparency, clear communication regarding the working principles of the LLM Application with the users is necessary. This is an important factor in building trust among the users towards the application. To avoid biased data outputs, a thorough curation of data used while training must be done. Along with this, fairness can be maintained by post-processing the generated data for biased results.
Regular monitoring for ethical concerns and biased data applications must be done to ensure user privacy. Robust security measures should be implemented to protect user data that complies with the relevant data protection regulations.

Conclusion
LLMs are revolutionizing the user engagement space, and natural language processing has fueled the growth of AI-driven technologies. Building an LLM-based application is a venture that comes along with various challenges, demanding situations as well as ethical responsibilities. From choosing the right technology stack to maintaining the standards of ethics and fairness, LLM Application development sure sounds like a challenge.
With Proper LLM training, planning an efficient scaling model, and developing an application to achieve the required goals is feasible. With the right approach towards development, strategizing the right use of available resources, and ethical considerations, creating and deploying an LLM Application can be a beneficial enterprise.
At Mindbowser, we provide comprehensive and cutting-edge solutions for automating Large Language Models. Our diverse range of services in LLM automation includes models like LLama, GPT-3, GPT-4, and BERT. We strive to equip you with best-in-class language comprehension and text generation capabilities.
Every LLM-based application created is a remarkable contribution to the rapidly growing field of Artificial Intelligence, and you can be a part of it too!
Frequently Asked Questions
An LLM or a “Large Language Model” is an advanced natural language processing model that is trained using huge amounts of data. This equips them with the capability to understand and generate human-like text. These models are trained using techniques such as deep learning. They are generally used to perform tasks like understanding input languages, generating meaningful outputs, and translation, etc.
Examples of LLM include models like – GPT3(Generative Pre-Trained transformer-3), T5(Text-to-text transformer), and BERT(Bidirectional Encoder Representations from Transformers). GPT-3 is the third iteration of the GPT module and is trained on a massive scale covering up to 175 billion parameters. Whereas, T5 is an LLM developed by Google and has shown remarkable efficiency in operations like summarization and translation, etc. BERT is also an LLM developed by Google which employs a bi-directional context understanding unlike other LLMs.
LLMs are trained by exposing them to a vast amount of pre-existing data This diverse textual data helps the LLM to understand and predict words and information in a sequence. This capability of identifying patterns can be used to train a model for a specific dataset to specialize its application.
The technology stack used in Large language models includes architectures to handle sequential data efficiently, which equips them with the capability to perform natural language prov+cessing tasks. To understand the data during the training phase, deep neural networks are used to perform deep learning tasks that help the model to understand complex data patterns, Moreover, the computational resources used to train LLms include computing frameworks to distribute the training processes across multiple GPUs and TPUs.
Large Language Models are versatile tools and have a wide range of applications across natural language processing. These applications can perform tasks like- generating diverse content, translation, sentiment analysis of input data, creating chatbots, generating code, filtering content, etc. LLMs also show a significant capability in named entity recognition, identifying and classification of input data, etc. LLMs with these remarkable capabilities are becoming indispensable for advancements in the field of AI-driven data generation.


