



















 BLOGS
BLOGS  NEWSROOM
NEWSROOM  CASE STUDIES
CASE STUDIES  WEBINARS
WEBINARS  PODCASTS
PODCASTS  ASSET HUB
ASSET HUB  EVENT CALENDAR
EVENT CALENDAR 

























Today AI and Natural Language Processing is gaining rapid significance, specifically with no-code AI-driven platforms becoming a boon for us. It showcases NLP’s growth, which is expected to increase nearly 14x times in 2025, taking off from approximately $3 billion to $43 billion.
Within this significant landscape, Custom LLMs have gained popularity for their ability to comprehend and generate unique solutions. Many pre-trained modules like GPT-3.5 by Open AI help to cater to generic business needs. As every aspect has advantages and disadvantages, the most exceptional LLMs may also face difficulties with specific tasks, industries, or applications.
So how can you overcome these challenges?
The process of fine-tuning Custom LLMs helps you solve your unique needs in these specific contexts. By customizing and refining the LLMs, businesses can leverage their potential and achieve optimal performance in targeted scenarios.
In this blog, we will discuss the importance of customizing Custom LLMs to improve their performance. We will explore different techniques and strategies that can be implemented in these models for specific tasks and applications.
Customizing LLMs- Power of Fine-Tuning
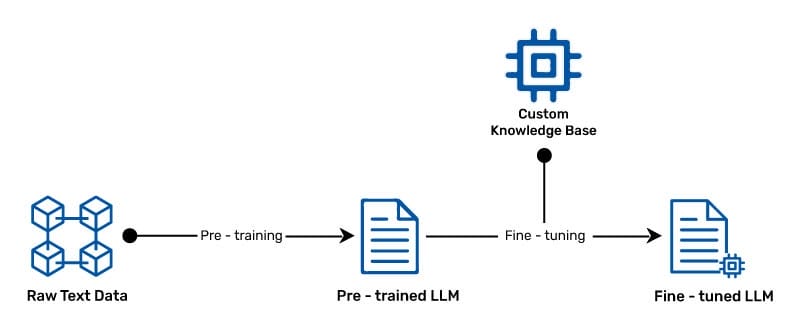 Fine-tuning is an important technique in customizing LLMs for specific tasks. It involves training a pre-trained model on a task-specific dataset. The process allows the model to adapt to the nuances of the target application without hindering the valuable information it gained during pre-training. The advantage of fine-tuning lies in the ability to strike a balance between implementing the available knowledge included in the pre-trained model and customizing it in a specialized domain.
Fine-tuning is an important technique in customizing LLMs for specific tasks. It involves training a pre-trained model on a task-specific dataset. The process allows the model to adapt to the nuances of the target application without hindering the valuable information it gained during pre-training. The advantage of fine-tuning lies in the ability to strike a balance between implementing the available knowledge included in the pre-trained model and customizing it in a specialized domain.
Related read: Building Your First LLM Application: A Beginner’s Guide
Adapting to Task-Specific Features
With fine-tuning, you are enabled to extract the task-specific features from the pre-trained Custom LLMs. These features are important to understanding the intricacies of the task and can greatly improve model performance.
You are specific to fine-tuning the layers of models, focusing on those that capture high-level domain-specific information. This approach helps maintain a general understanding of language while refining the model for the intended task.
Optimizing Hyperparameters
Fine-tuning offers the flexibility to adjust learning rates, striking a balance between the overarching patterns acquired during pre-trained and the important details needed for Custom LLMs task-specific performance.
With fine-tuning, you can experiment with different batch sizes and epochs, while customizing the training process to the characteristics of the new data.
Domain Adaptation
The process facilitates the transfer of knowledge from the pre-trained model to the specific domain of interest, empowering when dealing with limited data for the target task with Custom LLMs.
Fine-tuning provides a valuable opportunity to address any inherent bias present in the pre-trained model. It enables the creation of a customized model that aligns with the particular requirements of the application.
Regularization and Control
Fine-tune techniques incorporate regularization effectively protecting against overfitting on task-specific data for Custom LLMs. It ensures the model maintains a strong ability to generalize well, improving performance and reliability.
Experts can fine-tune the model iteratively, observing performance on validation data and making changes as needed. Such controlled adaption is important for achieving optimal results.
Optimize your LLMs today for task-specific solutions! Enhance performance with fine-tuning techniques. Hire our developer now!
The Process of Customizing LLMs for Specific Tasks
Customizing LLMs for specific tasks involves a systematic process that includes domain expertise, data preparation, and model adaption. The whole journey from choosing the right pre-trained model to fine-tuning for optimal performance needs careful consideration and attention to detail. To simplify this for you, we have provided a step-by-step guide to the process.
Define the Task and Requirements
When you begin with a specific task, it is important to clearly define the objective and desired goals. Identify your key requirements which ensure the results align with your expectations.
To effectively address your task, you need to consider the nature of the data at hand. Understand their characteristics such as size, complexity, and relevance to the application. Now you are ready to customize your approach to the task with a well-defined motive towards the LLMs in hand.
Selecting the Pre-Trained Model
When considering pre-trained models for your task, it is important to evaluate them based on their architecture, size, and relevance to the specific task at hand, especially with Custom LLMs. Consider whether the model’s structure aligns with the requirements of your tasks and assess its size for the available resources. The model’s performance on similar tasks should be assessed to capture relevant features.
Data Collection and Cleaning
Collect all the relevant datasets to encompass the significant information and examples for Custom LLMs. This dataset will serve as the foundation for training and assessing your selected models.
Once you have all your collected data, the next crucial step is to clean and preprocess it. The process involves ensuring consistency and compatibility with the chosen pre-trained model. Evaluate any issues such as missing values, outliers, or anomalies in the dataset that may affect the quality of your results.
Such important steps can help you create a standardized and reliable dataset that aligns with the requirements of both your task and the chosen model.
Model Architecture Adjustment
While working with a pre-trained model, it’s important to customize the architecture to align with your specific tasks. In modification of architecture, you can make changes to the layers, structure, or aspects of the model to align it with the requirement.
The output layer of a model generates predictions or classifies inputs into separate categories, a crucial step in Custom LLMs. To ensure relevant results, you need to adjust the output layer based on two factors: the number of classes and the nature of the target variable.
Fine-tuning involves making adjustments to the pre-trained layers of the model to enhance its performance on your specific tasks. The complexity of your task plays an important role in determining how much fine-tuning is needed. For simpler tasks, you may need to make minor changes, while more complex tasks may require deeper adjustments or even retaining certain layers.
Our Projects
Changing the Office Dynamics for a Platform Promoting Diversity and Inclusion
Delve into the journey of a leading DEI Operating System, as it overcomes the challenges within its internal features. Faced with an old user interface and inefficient functionality, the organization recognized the need for modernization to improve user experience and efficiency. Through strategic solutions and innovative enhancements, we navigated these challenges, reshaped office dynamics, and established a more inclusive workplace environment.
Fine-Tuning Process
When working with Custom LLMs, starting with a pre-trained model helps gather general patterns and features from the original dataset. Leveraging this knowledge enhances the model’s understanding.
Fine-tuning entails training the model on a task-specific dataset, refining its representations for your specific task. Monitoring its performance on a separate validation dataset is crucial during training. This allows evaluation of generalization to new data and prevents overfitting. Frequent monitoring facilitates informed decisions on adjusting hyperparameters or stopping training.
Evaluation and Iterative Refinement
To evaluate the performance of the model, it is important to assess its performance on the test set, a crucial step in Custom LLMs. This monitoring provides valuable insights into how well the model generalizes to unseen data and performs in real-world settings.
It is essential to analyze metrics relevant to the specific task at hand, such as accuracy, precision, recall, and others. These metrics offer an understanding of the model’s performance, guiding adjustments and refinements to enhance its effectiveness.
Deployment and Monitoring
After you are done with fine-tuning and optimizing the model, now you deploy it to the target environment where it will be used in real-world scenarios, a crucial step in Custom LLMs. The process involves setting up the necessary infrastructure, such as servers or cloud platforms, to host the model and make it accessible to users or other systems.
The next step is to collect data on how the model is performing, measuring key metrics, and analyzing its behavior in different use cases. Feedback loops help in the continuous improvement of the deployed model, involving collecting feedback from users, stakeholders, or other sources to gain insights into how well the model is meeting their needs and expectations.
Documentation and Knowledge Transfer
To ensure effective collaboration and future maintenance of the Custom LLMs, it is important to document the entire process. The documentation should have the decisions made, parameters used, and outcomes observed throughout the process.
Provide an overview of the project and the purpose of customizing the model. Describe the data used for training and fine-tuning the model. You can include details about the data sources, preprocessing steps, and any data augmentation techniques applied.
Related read: The Top Most Useful Large Language Model Applications
Integrate Customized LLMs for Your Specific Tasks with Mindbowser
In the dynamic landscape of natural language processing, the customization of Custom LLMs for specific tasks stands as a powerful beacon for innovation and problem-solving. As we explored some important processes of customizing pre-trained models to unique applications, the importance of this approach becomes evident.
Customization, backed by a fine-tuning process, allows practitioners to strike a balance between the understanding embedded in pre-trained models and the intricacies of task-specific domains. The adaptability of LLMs empowers industries and researchers to leverage the capabilities of these models across different applications, i.e. from healthcare and financial services to customer and support services.
At Mindbower, we help you explore extraordinary opportunities for customization in LLMs, establishing advancements in natural language understanding and problem-solving. Whether you are delving into sentiment analysis, entity recognition, or another specialized task we guide you to unleash the full potential of language models.


