



















 BLOGS
BLOGS  NEWSROOM
NEWSROOM  CASE STUDIES
CASE STUDIES  WEBINARS
WEBINARS  PODCASTS
PODCASTS  ASSET HUB
ASSET HUB  EVENT CALENDAR
EVENT CALENDAR 



























TL:DR
- Databricks’ medallion architecture (Bronze/Silver/Gold) maps directly to the FHIR-to-OMOP pipeline stages: raw NDJSON in, research-ready OMOP tables out.
- Delta Lake handles versioning, rollback, and audit trails required for healthcare compliance.
- Auto-scaling handles both large monthly Epic bulk exports (2M+ patients) and daily incremental updates without overprovisioning.
- ConnectHealth feeds the Bronze layer, pulling FHIR exports from Epic, Cerner, and 20+ EHRs before Databricks runs the transformation.
Healthcare organizations generate data at unprecedented scales—millions of patient encounters, billions of clinical observations, and terabytes of diagnostic information. Traditional data processing approaches, built for smaller volumes and simpler structures, struggle with modern healthcare’s complexity and scale.
Enter cloud-native data platforms like Databricks, which provide the computational power, scalability, and analytical capabilities needed for enterprise healthcare data processing and FHIR-to-OMOP transformations.
Why Databricks Excels for Healthcare
Unified Analytics Platform
Databricks combines data engineering, machine learning, and analytics in a single platform, eliminating the traditional barriers between operational data processing and advanced analytics. For healthcare organizations, this means:
- Single platform for ETL, analytics, and ML
- Collaborative environment for data teams and researchers
- Integrated security across all analytical workloads
- Cost optimization through unified resource management
- Built-in capabilities that speed up FHIR-to-OMOP pipelines
Auto-Scaling Architecture
Healthcare data volumes vary dramatically—monthly Epic exports might process 2M patient records, while daily incremental updates handle thousands. Databricks auto-scaling automatically adjusts compute resources based on workload demands:
- Pay for actual usage rather than peak capacity
- Automatic cluster management reduces operational overhead
- Burst processing handles large monthly exports efficiently
- Cost optimization through intelligent resource allocation
- Efficient scaling for FHIR-to-OMOP workflows
Delta Lake Foundation
Delta Lake provides ACID transactions, versioning, and schema evolution—critical capabilities for healthcare data management:
- Data versioning enables rollback of failed processing
- Schema evolution accommodates changing FHIR specifications
- ACID transactions ensure data consistency across tables
- Time travel supports regulatory audit requirements
- Reliable data management for FHIR-to-OMOP conversion
The Medallion Architecture for Healthcare
Databricks’ medallion architecture (Bronze, Silver, Gold) maps perfectly to healthcare data processing requirements and FHIR-to-OMOP transformation pipelines:
Bronze Layer: Raw Healthcare Data
- FHIR NDJSON files from Epic bulk exports
- Data validation and integrity checking
- Metadata capture for lineage tracking
- Error quarantine for data quality issues
- Forms the base layer for FHIR-to-OMOP workflows
The Bronze layer serves as the single source of truth, preserving raw FHIR data exactly as received from Epic while adding essential metadata for processing and compliance in the FHIR-to-OMOP conversion process.
In Mindbowser’s implementations, the FHIR NDJSON landing in Bronze comes through ConnectHealth, our integration platform, which pulls bulk exports from Epic, Cerner, and 20+ other EHRs, with Helix AI handling the resource mapping. Databricks then carries it from Bronze to research-ready Gold.
Silver Layer: Cleansed and Enriched Data
- Concept enrichment with OMOP vocabulary lookups
- Data quality validation and standardization
- Reference resolution maintaining clinical relationships
- Domain-based classification for intelligent routing
The Silver layer transforms raw FHIR into analytics-ready data while preserving clinical context and ensuring data quality through automated validation in support of FHIR-to-OMOP requirements.
Gold Layer: Research-Ready Analytics Tables
- OMOP CDM compliance for cross-institutional research
- Optimized table structures for analytical queries
- Aggregated measures for population health insights
- ML-ready features for predictive modeling
- Final target structure for FHIR-to-OMOP outputs
The Gold layer provides research teams with consistently structured, high-quality data optimized for analytical workloads and machine learning applications, enabling full value from FHIR-to-OMOP transformations.
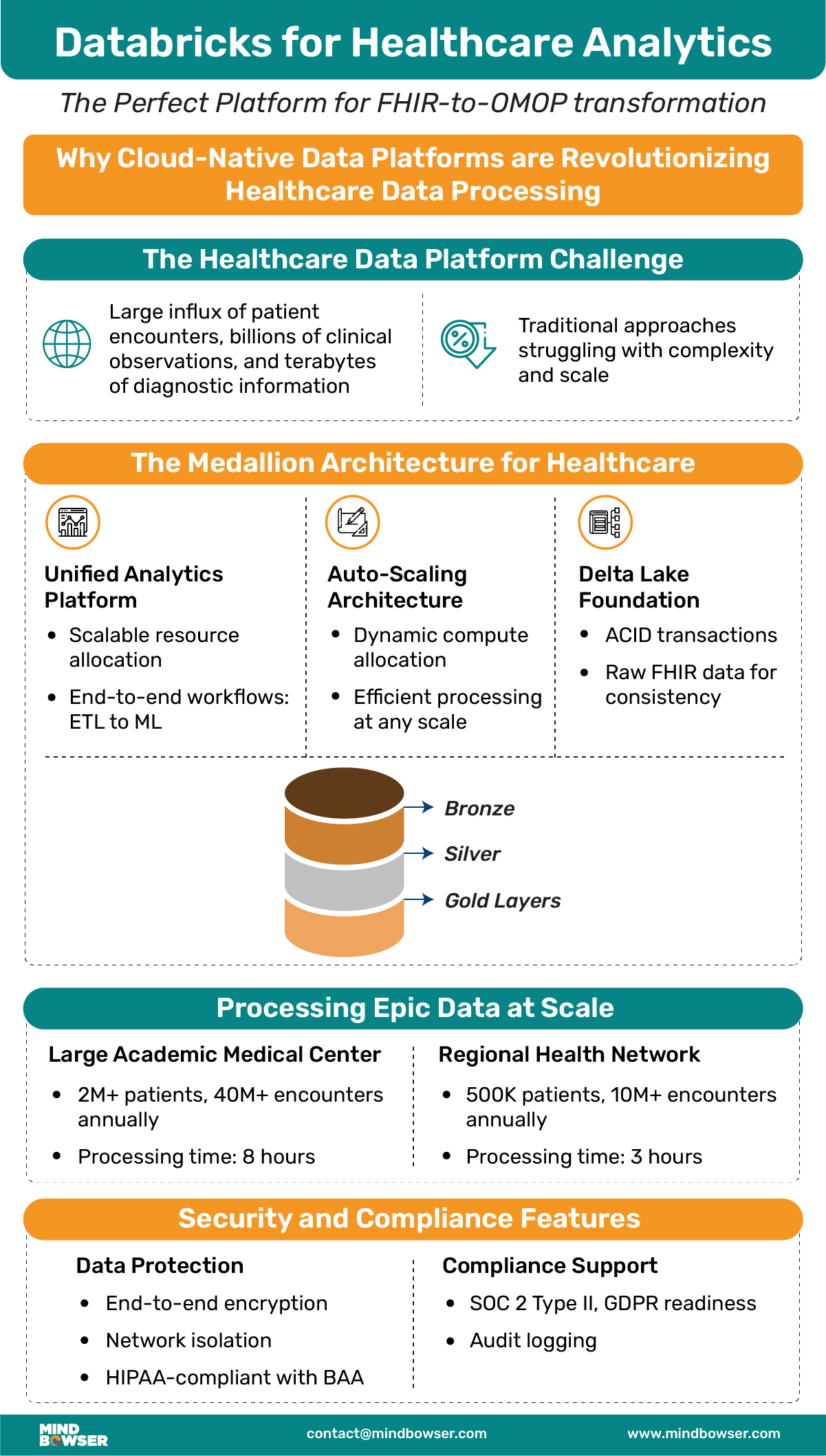
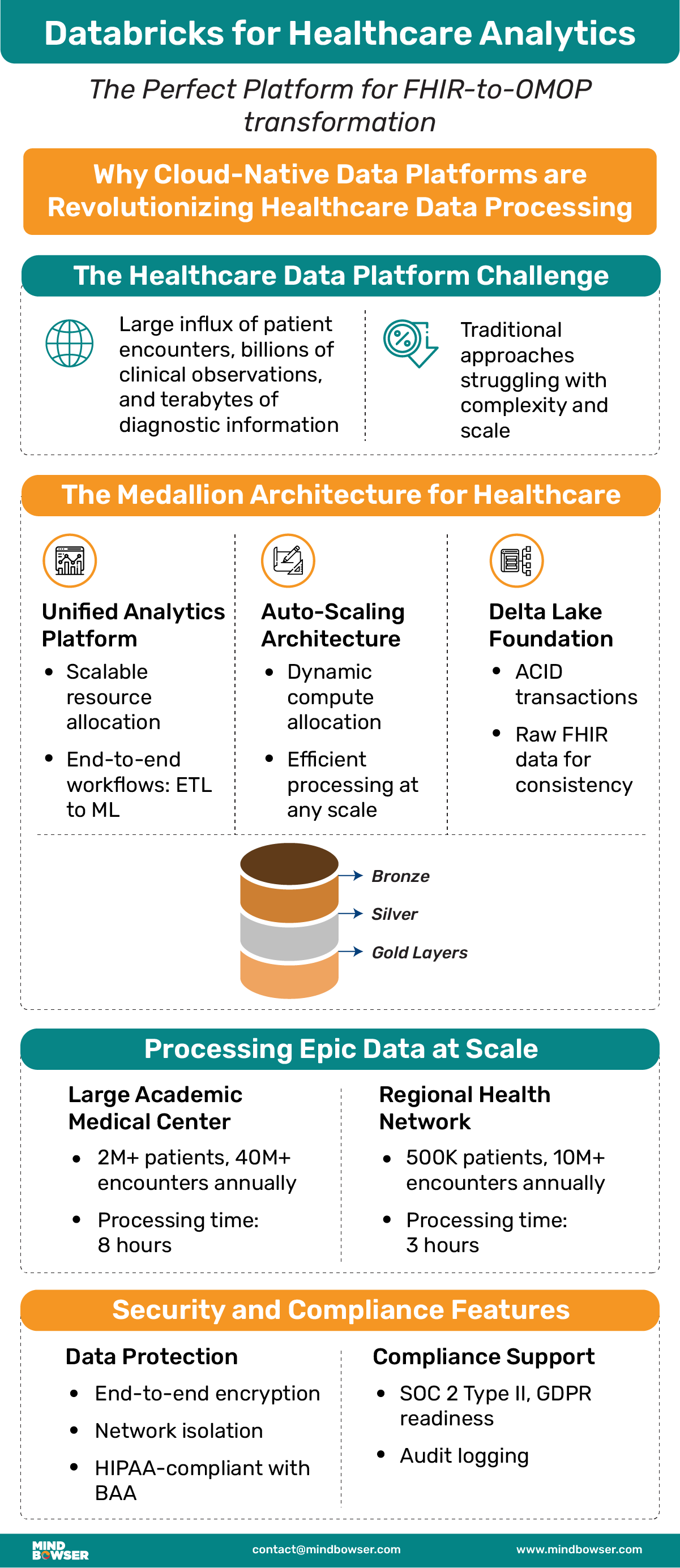
Processing Epic Data at Scale
The following are representative configurations based on Mindbowser implementation benchmarks; actual figures vary by Epic tenant size, export frequency, and cluster configuration:
Large Academic Medical Center:
- Data Volume: 2M+ patients, 40M+ encounters annually
- Processing Time: 8 hours for complete monthly export
- Compute Configuration: 20-node cluster with auto-scaling
- Cost: $8K–15K monthly for complete processing pipeline
- Supports monthly FHIR-to-OMOP conversions
Regional Health Network:
- Data Volume: 500K patients, 10M+ encounters annually
- Processing Time: 3 hours for weekly incremental updates
- Compute Configuration: 10-node cluster with burst scaling
- Cost: $2K–5K monthly for automated processing
- Handles weekly FHIR-to-OMOP data loads
The 4-Stage FHIR Processing Pipeline
Databricks’ distributed processing architecture enables sophisticated multi-stage pipelines for FHIR-to-OMOP transformations:
Stage 1: Bulk Data Ingestion
```python
# Parallel processing of NDJSON files
fhir_data = (spark.read
.option("multiline", "false")
.json("s3://healthcare-data/fhir-export/")
.cache())
` ` `Stage 2: Intelligent Transformation
```python
# Domain-based routing with UDFs
encounter_data = (fhir_data
.filter(col("resourceType") == "Encounter")
.withColumn("omop_concepts", enrich_with_vocabulary_udf(col("type.coding")))
.withColumn("target_tables", route_by_domain_udf(col("omop_concepts"))))
` ` `Stage 3: Fragment Generation
```python
# Generate staging fragments for each OMOP table
visit_fragments = encounter_data.select(
lit("visit_occurrence").alias("table_name"),
col("id").alias("record_id"),
# ... OMOP visit_occurrence columns
).write.mode("append").option("sep", "\t").csv("staging/")
` ` `Stage 4: Consolidation and Loading
```python
# Merge fragments and resolve conflicts
final_visits = (spark.read.csv("staging/visit_*.tsv")
.groupBy("record_id")
.agg(merge_conflict_resolution_udf(collect_list("*")))
.write.saveAsTable("omop.visit_occurrence"))
` ` `These stages are foundational to any reliable FHIR-to-OMOP data pipeline.
Stages 3 and 4: fragment generation and consolidation are covered in depth in our fragment processing deep dive.
Transform FHIR Data into Actionable Insights with Databricks
Performance Optimization Strategies
Healthcare workloads benefit from specific Databricks optimizations that directly impact FHIR-to-OMOP transformation efficiency:
Data Partitioning
- Partition by date for temporal queries
- Z-order optimization for multi-dimensional filtering
- Bloom filters for efficient joins
- Liquid clustering for optimal data layout
Compute Optimization
- Spot instances for batch processing cost reduction
- Photon engine for accelerated SQL performance
- GPU clusters for machine learning workloads
- Serverless compute for ad-hoc analytical queries
Storage Optimization
- Data compression reducing storage costs by 70%+
- Intelligent caching for frequently accessed data
- Lifecycle policies for automated data archival
- Multi-cloud storage for disaster recovery
Security and Compliance Features
Databricks provides enterprise-grade security essential for healthcare and FHIR-to-OMOP processing:
Data Protection
- End-to-end encryption with customer-managed keys
- Network isolation through private networking
- Row-level security for granular access control
- Column masking for PHI protection
Compliance Support
- HIPAA compliance with Business Associate Agreement
- SOC 2 Type II certification for security controls
- GDPR readiness for data privacy requirements
- Audit logging for comprehensive activity tracking
Machine Learning for Healthcare Insights
Databricks’ unified platform enables advanced analytics on OMOP data, driven by FHIR-to-OMOP alignment:
Clinical Prediction Models
- Patient risk stratification using longitudinal data
- Readmission prediction from encounter patterns
- Drug adverse event detection through surveillance algorithms
- Clinical deterioration alerts from vital sign trends
Population Health Analytics
- Cohort identification for clinical trials
- Quality measure calculation for value-based care
- Health disparities analysis across demographics
- Resource utilization optimization through predictive modeling
Cost Optimization Strategies
Healthcare organizations can optimize Databricks costs through strategies that also improve FHIR-to-OMOP workflows:
Right-Sizing Compute
- Job clustering for batch workloads
- Serverless SQL for interactive analytics
- Pools for faster cluster startup
- Auto-termination preventing idle costs
Data Lifecycle Management
- Hot/cold tiering based on access patterns
- Automated archival for compliance retention
- Compression optimization reducing storage costs
Query optimization minimizing compute requirements
Getting Started with Healthcare Analytics
Organizations planning Databricks implementation should consider:
- Data volume assessment for capacity planning
- Security requirements for healthcare compliance
- Integration patterns with existing healthcare systems
- Team training for platform adoption
- Cost modeling for budget planning
- FHIR-to-OMOP roadmap design and execution
Where Healthcare Analytics on Databricks Is Headed
Databricks’ roadmap aligns with healthcare’s evolving needs:
- Real-time processing for operational analytics
- Federated learning for multi-site research
- AutoML capabilities democratizing machine learning
- Lakehouse architecture unifies data warehousing and ML
Continuous innovation in FHIR-to-OMOP transformation methods
How Databricks Fits Into the FHIR-to-OMOP Analytics Workflow
Databricks is one part of the broader FHIR-to-OMOP analytics workflow. The platform can support large-scale ingestion, transformation, validation, and analytics, but the success of the pipeline depends on how healthcare data is modeled, governed, and mapped from the beginning.
In a typical FHIR-to-OMOP architecture, raw FHIR resources move into a landing or bronze layer, where source fidelity is preserved. Transformation logic then cleans, normalizes, and enriches the data before it moves into curated silver and gold layers. From there, mapped OMOP tables can support cohort analysis, research queries, quality reporting, population health, and AI-ready datasets.
This is why Databricks works well for high-volume healthcare data environments. Its lakehouse pattern can help teams process fragmented FHIR resources, maintain lineage, apply validation rules, and scale analytics workloads across clinical, operational, and research use cases.
Read the broader guide on FHIR to OMOP conversion for healthcare analytics to see how Databricks-based pipelines connect with mapping, standardization, validation, and downstream healthcare analytics workflows.
Data engineering note: A Databricks implementation should not stop at platform setup. Healthcare teams also need ingestion design, terminology mapping, PHI-aware access controls, data quality checks, lineage, monitoring, and reusable transformation logic. Mindbowser helps teams build these foundations so FHIR-to-OMOP pipelines are reliable, scalable, and analytics-ready.
Part of the FHIR-to-OMOP Series
This page covers the architecture of how Databricks’ medallion layers map to FHIR-to-OMOP pipeline stages. The rest of the series:
Why FHIR-to-OMOP is the future of healthcare analytics the awareness pillar: what FHIR and OMOP are, why the gap between them matters, and what automated pipelines solve.
The ROI of automated FHIR-to-OMOP: the cost case for traditional custom builds at $900K–1.8M vs. automated at $200K–400K, with a 276% first-year ROI breakdown.
Fragment processing deep dive into the engineering inside Stages 3-4 above: fragment lifecycle, parallel processing, conflict resolution at 2,000+ records/second.
Conclusion
The convergence of cloud-native platforms, healthcare standards like FHIR and OMOP, and advanced analytics capabilities creates unprecedented opportunities for evidence-based care delivery and medical discovery.
Organizations that embrace these modern data architectures, especially through well-architected FHIR-to-OMOP strategies, will lead in transforming healthcare through data-driven insights.
FHIR-to-OMOP transformation converts healthcare data from the HL7 FHIR format into the OMOP Common Data Model, enabling standardized analytics, research, and interoperability across institutions.
Databricks offers scalable compute, Delta Lake reliability, and an auto-scaling architecture that efficiently processes complex FHIR datasets and maps them to OMOP, all within a single collaborative platform.
With auto-scaling clusters, distributed Spark processing, and intelligent resource management, Databricks can ingest and transform millions of records in hours—whether for monthly full loads or weekly incremental updates.
