



















 BLOGS
BLOGS  NEWSROOM
NEWSROOM  CASE STUDIES
CASE STUDIES  WEBINARS
WEBINARS  PODCASTS
PODCASTS  ASSET HUB
ASSET HUB  EVENT CALENDAR
EVENT CALENDAR 



























Epic Systems holds more than 250 million patient records across leading health systems worldwide. It’s built to support day-to-day clinical workflows, and it does that well. But when it comes to pulling that data out and reshaping it for research, things get tricky.
Researchers and data teams need access to Epic’s clinical data, not for treating patients, but for analyzing trends, outcomes, and patterns. The problem? That data isn’t analytics-ready out of the box. So the real question becomes: how do you take Epic’s FHIR data and turn it into something clean, usable, and research-ready—without getting buried in manual work?
FHIR R4: Epic’s Data Export Standard
Epic has standardized on FHIR R4 for bulk data export, providing a modern API-based approach to extracting large datasets. The FHIR Bulk Data Export specification enables:
- Scheduled exports of entire patient populations
- NDJSON format for efficient streaming processing
- OAuth 2.0 authentication for secure access
- Incremental updates for changed records only
This standardization means healthcare organizations can build automated pipelines that work consistently across Epic implementations, forming the core of a scalable data pipeline architecture.
The Modern Data Pipeline Architecture
A robust Epic-to-research pipeline requires five key components:
1. Secure Integration Layer
- Epic FHIR API connectivity with proper authentication
- Automated scheduling for weekly/monthly exports
- Error handling and retry logic for reliable operation
- Audit logging for compliance and monitoring
2. Cloud-Native Processing Platform
- Auto-scaling compute to handle variable data volumes
- Distributed processing for large patient populations
- Delta Lake storage for versioned data management
- Real-time monitoring of pipeline health
3. Intelligent Transformation Engine
- Domain-based routing using medical terminology
- Quality validation at each processing stage
- Reference resolution to maintain data relationships
- Multi-format output supporting various research needs
4. Research-Ready Data Mart
- OMOP CDM compliance for cross-institutional studies
- Optimized analytics tables for fast query performance
- Data governance controls for appropriate access
- API endpoints for research tool integration
5. Quality Assurance Framework
- Automated testing of transformation accuracy
- Data completeness monitoring across all tables
- Terminology validation for concept mappings
- Performance benchmarking against SLAs
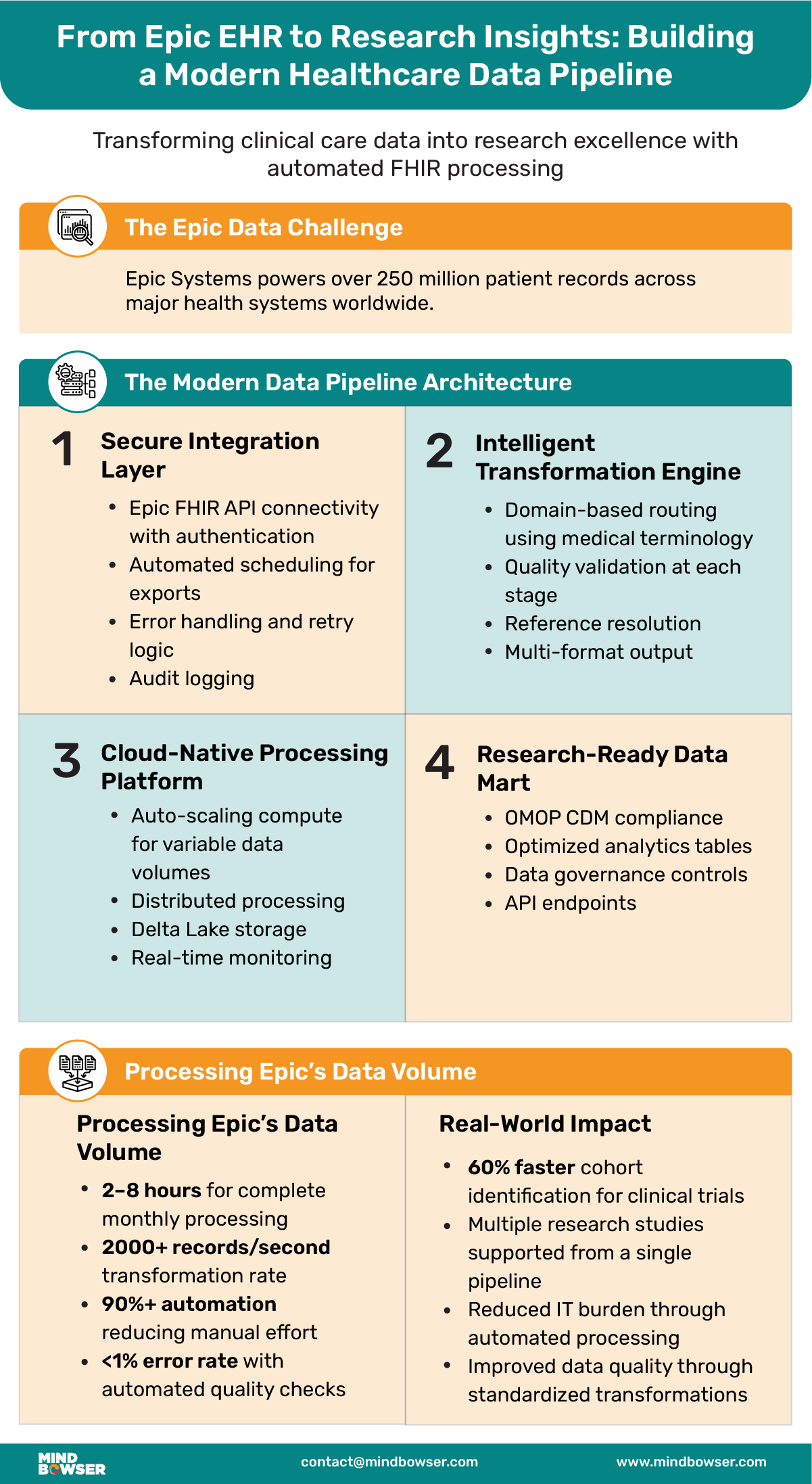
Processing Epic’s Data Volume
Modern health systems generate massive data volumes:
- Large Academic Medical Centers: 2M+ patients, 40M+ encounters annually
- Regional Health Networks: 500K patients, 10M+ encounters annually
- Processing Requirements: Handle TB-scale datasets efficiently
The pipeline must scale dynamically to accommodate these volumes while maintaining processing speed and data quality.
Real-World Implementation Results
Organizations implementing automated Epic-to-research pipelines report significant improvements:
Performance Metrics:
- 2-8 hours for complete monthly processing
- 2000+ records/second transformation rate
- 90%+ automation reducing manual effort
- <1% error rate with automated quality checks
Business Impact:
- 60% faster cohort identification for clinical trials
- Multiple research studies supported from single pipeline
- Reduced IT burden through automated processing
- Improved data quality through standardized transformations
Accelerate Research with a Custom Epic FHIR Data Pipeline
Technical Deep Dive: The 4-Stage Process
Stage 1: Epic FHIR Bulk Export
Epic generates NDJSON files containing FHIR resources:
- Patient demographics and identifiers
- Clinical encounters and visit details
- Diagnostic and procedure codes
- Laboratory results and vital signs
- Medication prescriptions and administrations
Stage 2: Intelligent Mapping
Each FHIR resource undergoes concept enrichment:
- Medical codes are validated against standard vocabularies
- Domain classifications determine target research tables
- Reference relationships are preserved for data integrity
- Quality issues are flagged for review
Stage 3: Fragment Processing
Data is organized into research-optimized structures:
- Tab-separated staging files for efficient bulk loading
- Primary key consolidation for duplicate resolution
- Multi-table output from single FHIR resources
- Parallel processing across multiple compute nodes
Stage 4: Research Database Loading
Final OMOP-compliant tables are populated:
- Clinical data tables (person, visit, condition, drug, measurement)
- Vocabulary tables with standard concept mappings
- Metadata tables tracking data provenance and quality
- Analytics-optimized indexes for fast query performance
Security and Compliance Considerations
Healthcare data pipelines must address stringent security requirements:
- HIPAA compliance throughout the entire pipeline
- End-to-end encryption for data in transit and at rest
- Role-based access controls limiting data exposure
- Audit trails for all data access and transformations
- Data retention policies aligned with regulatory requirements
ROI and Business Case
The investment in automated Epic-to-research pipelines delivers measurable returns:
Cost Savings:
- 70% reduction in ETL development costs
- 80% less manual effort for data preparation
- Faster time-to-insights enabling more research studies
Getting the most out of your healthcare data pipeline isn’t just about compliance — it’s also about efficiency. Streamlining your ETL process can save time, cut costs, and accelerate research. Check out our blog on ETL Optimization: Techniques to Boost Data Pipeline Performance to learn how to make your pipeline work smarter.
Strategic Benefits:
- Research competitiveness through rapid data access
- Grant funding advantages with robust data infrastructure
- Clinical trial efficiency through faster patient identification
- Population health insights supporting value-based care
Future-Proofing Your Investment
Modern pipelines should be designed for longevity:
- Standards-based architecture reducing vendor lock-in
- Cloud-native scalability accommodating growth
- API-first design enabling easy integration
- Automated maintenance minimizing ongoing costs
Getting Started
Organizations planning Epic-to-research pipelines should consider:
- Epic API access requirements and authentication setup
- Data volume assessment for sizing compute resources
- Research use case definition to guide table design
- Compliance framework for security and governance
- Pilot project scope to validate approach before full deployment
Turning clinical data from EHRs into valuable research insights is essential for today’s healthcare organizations. Having an automated pipeline that seamlessly handles Epic’s FHIR data—while ensuring quality, accuracy, and compliance—doesn’t just save time; it sets the stage for better patient care and groundbreaking medical discoveries.
