
GraphQL is a powerful tool for building APIs that has gained popularity in recent years. It was developed by Facebook in 2012 and released as an open-source project in 2015. Since then, GraphQL has been adopted by many companies as an alternative to REST APIs due to its flexibility, efficiency, and ease of use.
The blog focuses on “Getting Started with GraphQL” and covers various topics such as GraphQL architecture, schema, querying, mutations, tools, and libraries. We also explored how GraphQL can be used with REST APIs and how it can be applied in real-world applications.
We will start with understanding what exactly is GraphQL and how it differs from REST API;
GraphQL is a query language and runtime that enables clients to request data from APIs in a most flexible, efficient, and declarative manner. The clients can specify exactly what data they need, and the server will only return that data.
GraphQL helps in reducing the amount of over-or under-fetching of data that can occur with traditional REST APIs, resulting in faster and more efficient applications. It allows for more flexibility in fetching data, with the ability to combine and filter data from multiple sources. GraphQL provides tools for testing and debugging APIs and a rich ecosystem of libraries and frameworks for various programming languages.
Prefer watching over reading? Dive into our webinar video for a comprehensive overview.
The key difference between the two is that GraphQL is a specific query language and specification, while REST is more of an overarching architectural concept for how data should be transferred over a network.

Related read: GraphQL Tutorial: A Beginner’s Guide to Efficient Data Fetching
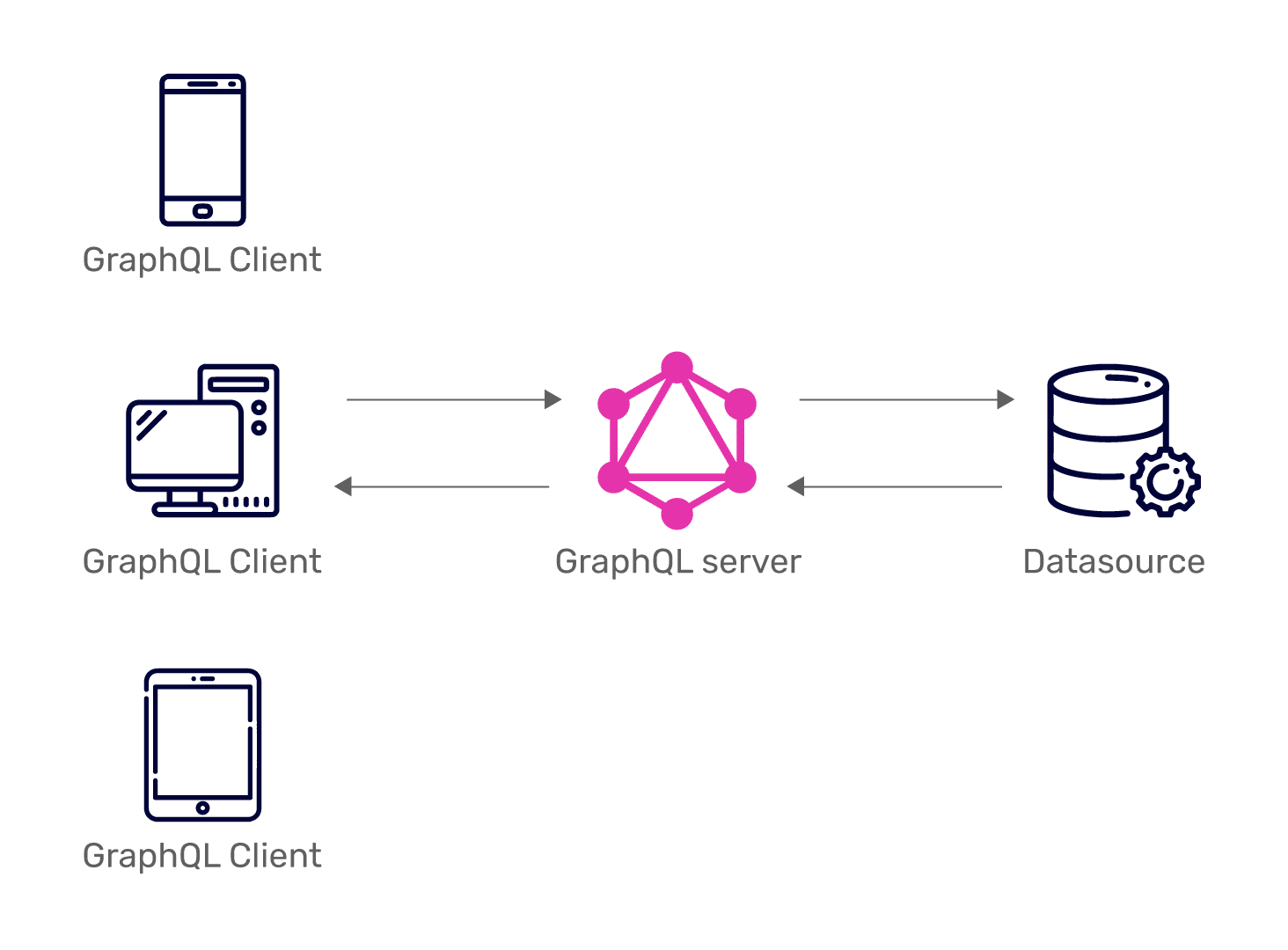
The GraphQL architecture consists of three layers: client, server, and database. GraphQL architecture allows you a clear specification of concerns between these three layers. The separation allows for greater flexibility and scalability in the design and implementation of the API. As GraphQL has a flexible and modular architecture, it can be used in a wide range of web applications and environments.
1. Client layer
The client layer is where the GraphQL client resides. The client layer is responsible for sending GraphQL queries to the server and receiving the response. The client can be a web or mobile application or any other application that can communicate with a GraphQL API. You can easily implement the client in different programming languages and frameworks.
2. Server layer
The GraphQL server layer is responsible for processing and executing GraphQL queries received from the client. The server consists of three components; schema, resolver functions, and execution engine. The schema defines the types and operations that can be performed on the data.
The resolver function is responsible for retrieving the data for a specific field in the schema. It can be written in any programming language and can retrieve data from any data source, such as a database or a REST API. The execution engine is the core component of the GraphQL server. It takes the query and schema, resolves the query using the resolver functions, and returns the response to the client.
3. Database layer
The database or data layer stores and retrieves the data needs to fulfill GraphQL queries. The data sources can include databases, REST APIs, or other data storage systems.
Related Read: A Guide To Minimum Viable Architecture Points For Any Startup
GraphQL works by enabling clients to request and retrieve data from servers in a flexible and efficient manner. It defines a schema that specifies the type of data available in the API and the relationships between them. The schema is then used by the server to process queries and mutations sent by the client.
🔸 Clients send a query
Clients send a GraphQL query to the server specifying what data is required. The query is generated in GraphQL’s query language, which is designed to be easy to read and write. The query specifies the fields the client requires and the relationship between them. The server receives the query and processes it again in the GraphQL schema.
🔸 Resolve the query
The GraphQL server receives the query and uses the schema to resolve it. The server validates the query against the schema and determines which resolver functions to call. Each resolver functions is responsible for retrieving the data for a specific field.
🔸 Return the data to the client
Once the data has been retrieved, the server returns it to the client in the desired query format.
🔸Update data with mutations
Clients can also update data in the server using mutations. Mutations are similar to queries, but they help in modifying the data in the server. The server receives the transformation and uses the schema to validate the data.
GraphQL consists of several key components that work together to enable clients to request data from APIs in a flexible and efficient manner. The components include;
Usually, a client interacts with the GraphQL server by sending queries and mutations using the GraphQL query language. Here are the steps involved in a typical client-server interaction with GraphQL.
🔷 Define the query
The process of retrieving data in GraphQL involves clients defining their required information through the query language. The process enables them to specifically request the exact data they need, without having to go through irrelevant or unnecessary information and streamlining and improving the efficiency of data retrieval.
🔷 Send the query
When the client wants to send a query, they can use HTTP or WebSocket protocols. The query can be sent as a POST request with a JSON payload, or as GET request with the query trying as a URL parameter. The standardized protocols simplify the process of querying data from the backend systems and ensure that the applications are reliable and performing well for end-user.
🔷 Processing the query
The query is processed in the server against the GraphQL schema. The process allows effective communication between the client and server, ensuring relevant data is exchanged and is according to the pre-defined standards by the schema.
🔷 Retrieve data
When the server receives a request for data, it takes action and pulls the relevant information from different sources. The retrieval process ensures that users receive accurate and updated information each time they interact with the application.
🔷 Return response
After the data is retrieved, the server starts with the processing and formatting of data before sending the response back to the client.
🔷 Client retrieves response
When the server returns the response to the client, it gains access to the retrieved data. The client can use the retrieved data for various purposes such as rendering the user interface and carrying out important operations.
GraphQL Schema is an essential component that helps in defining the structure of the data that can be queried or mutated by the client. The schema determines the types of data that can request, the relationship between the data, and entry points to access the data to the client.
The schema is usually defined through the Schema Definition Language (SDL) allowing the developers to define the types of queries and mutations processed by the API. The GraphQL Schema includes several components and we have listed them below;
🔹 Types
In GraphQL, types determine the shape and structure of the data that can be queried or mutated. The types can be in different forms such as a scaler, (e.g. String, Boolean, Int), object (e.g. User, Product), or custom types developed by the developers to fulfill the specific needs.
🔹 Field
Fields are an integral part of understanding how the information is structured in GraphQL. It includes three key elements such as name, a type, and an argument that help in filtering and sorting the data. The definition of fields within your project structure will help in creating an efficient system for accessing the relevant data.
🔹 Queries
Queries are the key building blocks for GraphQL which defines how data can be retrieved from the API. The operations can be performed and structured to request specific fields or sets of data in a flexible and efficient manner. With the help of queries, developers can create an interactive application that meets the user’s expectations.
🔹 Mutations
In GraphQL, mutations refer to the operations that are available to modify the data available in the database. The mutations carry out actions such as creating new entries or updating existing ones. This functionality poses greater control to the developers. With GraphQL mutations you can personalize the functionality of the application.
🔹 Subscription
Subscription acts like a backbone that provides clients with real-time updates. The subscriptions determine which operations can be subscribed and use to receive updates when its available. Such subscription functionality makes it possible for users to stay informed about changes and updates in the application.
When it comes to GraphQL, there are several types involved that can be defined in the schema. The GraphQL types define the shapes and size of the data that is required or mutated, and they can be used to model a wide range of data structures, from simple to complex objects.
Here are some of the common GraphQL Types;
In GraphQL, a query is nothing but a request for specific data from the API. The GraphQL query determines the shape of the data that the client has requested, which can be retrieved from different schema.
The GraphQL Query works similarly to JSON object, with nested fields and arguments to specify which data is requested. There are three components of GraphQL query;
🔸 Query operations
The query operation is particularly used to retrieve data on the same server or API. On the other hand, a mutation operation modifies the data on that server or API. The subscription operation is to update in real-time so that the clients are provided with continuous information whenever it’s available. Through such segments of operations, developers can build interactive user-interface and other features in the applications.
There are several fields that can be used to refine the data or the results. The query field includes nested options, aliases for simplicity, arguments that filter the data, and fragments to reuse commonly used segments. The specification in your queries ensures that the results presented back are tailored relevantly to the request of data.
Once the query is submitted to the server, it responds with data in the JSON object that matches the structure of the request. The returned data offers insights and information that help in making an informed decision for the project. The data can be analyzed and interpreted carefully to unlock new opportunities and possibilities for growth.
The query in GraphQL is written particularly in GraphQL query langauge, which is a textual representation of the data that the client wants to retrieve from the server.
Here is an example of a simple GraphQL query;


The subscription allows the server to push real-time updates to the client, instead of requiring the client to constantly poll the server for new data.
In a GraphQL API, the client pushes a request to the server and the server responds back with a single result. With the help of a subscription, the server sends the stream of data to the client which is kept in the subscription as it becomes available.
The subscription in GraphQL is defined as a subscription operation, which is similar to a query or mutation defining a set of rules for the server to send the updates to the client. The subscription can include arguments and variables to control being streamed and also includes nested data in the fields that retrieve the data back.
The developers use subscriptions in real-time applications such as community apps, social media platforms, or live sports updates. The client can get real-time updates and information in a very flexible and efficient manner without constantly refreshing the app or page.
Server
Client
Due to the flexibility and ability to streamline data collection and fetching, GraphQL has gained extreme popularity amongst different businesses. Here are some use cases for GraphQL;

Several social media platforms such as Facebook and Twitter, use GraphQL to power their API integration. GraphQL enables the platforms to effectively provide large data sets to users with the flexibility of specific information in real-time.

GraphQL can be used efficiently while building scalable e-commerce platforms that handle large amounts of user and product data. With the help of GraphQL, users have the leverage of requesting desired data without unnecessary data being transmitted and processed.

The developers can easily build APIs for mobile applications using graphQL. The usage of GraphQL for mobile applications allows these devices to easily retrieve data from the server to the client without any complex procedures. The GraphQL query language is considered to be suitable for all mobile devices as it can be optimized for low-bandwidth and intermittent network connections.

Businesses are utilizing GraphQL to empower content management systems (CMS) and other data-intensive applications or systems. Implementing GraphQL can help in reducing complexities and easy availability of requested data. Eventually, businesses can save a lot of time in processing large sets of data and provide a greater user experience.

GraphQL is a technology that enables a flexible and efficient way to collect and process data from different sources. It offers a number of advantages to your business over REST APIs, including reduced costs, enhanced performance, and more intuitive query language. With such advantages to businesses, GraphQL is gaining popularity amongst developers looking to build a scalable, data-intensive application.
To learn more about GraphQL and its aspects, you can watch out the webinar on “Getting Started with GraphQL” here.

We worked with Mindbowser on a design sprint, and their team did an awesome job. They really helped us shape the look and feel of our web app and gave us a clean, thoughtful design that our build team could...

The team at Mindbowser was highly professional, patient, and collaborative throughout our engagement. They struck the right balance between offering guidance and taking direction, which made the development process smooth. Although our project wasn’t related to healthcare, we clearly benefited...

Founder, Texas Ranch Security
Mindbowser played a crucial role in helping us bring everything together into a unified, cohesive product. Their commitment to industry-standard coding practices made an enormous difference, allowing developers to seamlessly transition in and out of the project without any confusion....

CEO, MarketsAI
I'm thrilled to be partnering with Mindbowser on our journey with TravelRite. The collaboration has been exceptional, and I’m truly grateful for the dedication and expertise the team has brought to the development process. Their commitment to our mission is...

Founder & CEO, TravelRite
The Mindbowser team's professionalism consistently impressed me. Their commitment to quality shone through in every aspect of the project. They truly went the extra mile, ensuring they understood our needs perfectly and were always willing to invest the time to...

CTO, New Day Therapeutics
I collaborated with Mindbowser for several years on a complex SaaS platform project. They took over a partially completed project and successfully transformed it into a fully functional and robust platform. Throughout the entire process, the quality of their work...

President, E.B. Carlson
Mindbowser and team are professional, talented and very responsive. They got us through a challenging situation with our IOT product successfully. They will be our go to dev team going forward.

Founder, Cascada
Amazing team to work with. Very responsive and very skilled in both front and backend engineering. Looking forward to our next project together.

Co-Founder, Emerge
The team is great to work with. Very professional, on task, and efficient.

Founder, PeriopMD
I can not express enough how pleased we are with the whole team. From the first call and meeting, they took our vision and ran with it. Communication was easy and everyone was flexible to our schedule. I’m excited to...

Founder, Seeke
We had very close go live timeline and Mindbowser team got us live a month before.

CEO, BuyNow WorldWide
If you want a team of great developers, I recommend them for the next project.

Founder, Teach Reach
Mindbowser built both iOS and Android apps for Mindworks, that have stood the test of time. 5 years later they still function quite beautifully. Their team always met their objectives and I'm very happy with the end result. Thank you!

Founder, Mindworks
Mindbowser has delivered a much better quality product than our previous tech vendors. Our product is stable and passed Well Architected Framework Review from AWS.

CEO, PurpleAnt
I am happy to share that we got USD 10k in cloud credits courtesy of our friends at Mindbowser. Thank you Pravin and Ayush, this means a lot to us.

CTO, Shortlist
Mindbowser is one of the reasons that our app is successful. These guys have been a great team.

Founder & CEO, MangoMirror
Kudos for all your hard work and diligence on the Telehealth platform project. You made it possible.

CEO, ThriveHealth
Mindbowser helped us build an awesome iOS app to bring balance to people’s lives.

CEO, SMILINGMIND
They were a very responsive team! Extremely easy to communicate and work with!

Founder & CEO, TotTech
We’ve had very little-to-no hiccups at all—it’s been a really pleasurable experience.

Co-Founder, TEAM8s
Mindbowser was very helpful with explaining the development process and started quickly on the project.

Executive Director of Product Development, Innovation Lab
The greatest benefit we got from Mindbowser is the expertise. Their team has developed apps in all different industries with all types of social proofs.

Co-Founder, Vesica
Mindbowser is professional, efficient and thorough.

Consultant, XPRIZE
Very committed, they create beautiful apps and are very benevolent. They have brilliant Ideas.

Founder, S.T.A.R.S of Wellness
Mindbowser was great; they listened to us a lot and helped us hone in on the actual idea of the app. They had put together fantastic wireframes for us.

Co-Founder, Flat Earth
Ayush was responsive and paired me with the best team member possible, to complete my complex vision and project. Could not be happier.

Founder, Child Life On Call
The team from Mindbowser stayed on task, asked the right questions, and completed the required tasks in a timely fashion! Strong work team!

CEO, SDOH2Health LLC
Mindbowser was easy to work with and hit the ground running, immediately feeling like part of our team.

CEO, Stealth Startup
Mindbowser was an excellent partner in developing my fitness app. They were patient, attentive, & understood my business needs. The end product exceeded my expectations. Thrilled to share it globally.

Owner, Phalanx
Mindbowser's expertise in tech, process & mobile development made them our choice for our app. The team was dedicated to the process & delivered high-quality features on time. They also gave valuable industry advice. Highly recommend them for app development...

Co-Founder, Fox&Fork





