
Web scraping is the process of automatically extracting data from websites using software or scripts. It involves fetching the HTML content of a web page and parsing it to retrieve specific information, such as text, images, links, or structured data. Web scraping enables users to collect large amounts of data quickly and efficiently, which can be used for various purposes, including research, analysis, and decision-making. Web scraping is about extracting data from websites by parsing its HTML. On some sites, data is available to download in CSV or JSON format, but in some cases, that’s not possible, and for that, we need web scraping.
Web scraping can be done using different tools and techniques, ranging from simple manual copying and pasting to sophisticated automated scripts. Some common methods include using HTTP requests to fetch web pages, parsing HTML or XML to extract relevant data, and utilizing APIs provided by websites. However, web scraping should be done responsibly and in compliance with websites’ terms of service, robot.txt files, and applicable laws to avoid legal issues and maintain ethical standards.
Large datasets can be scooped up from websites using web scraping techniques. Here are some of the common types of web data that can be extracted:
➡️ Product Information: This includes details like prices, descriptions, specifications, availability, and reviews from e-commerce platforms or product listing websites.
➡️ News Articles: Web scraping can be used to gather news stories and articles from various online publications.
➡️ Real Estate Listings: Websites with property listings can be scraped to collect data on houses, apartments, or commercial spaces for sale or rent.
➡️ Social Media Data: Public social media posts, profiles, and comments can be scraped, though terms of service restrictions apply to some platforms.
➡️ Financial Data: Stock quotes, currency exchange rates, and other financial information can be extracted from financial websites.
➡️ Scientific Data: Research publications, datasets, and other scientific information can sometimes be scraped from publicly accessible online repositories.
It’s important to remember that ethical considerations and website terms of service should always be respected when web scraping.
Web scrapers are powerful tools that extract specific data points from websites, ensuring users collect only the most relevant information efficiently. By focusing on targeted data extraction, web scrapers save time and provide clean, concise datasets for further analysis.
The process begins with providing the scraper with the necessary URLs, followed by parsing the HTML, CSS, and JavaScript elements to navigate the web pages. The scraper then identifies and extracts the desired data points based on the user’s requirements, outputting the data in a structured format such as Excel, CSV, or JSON. This targeted approach results in a focused dataset ready for integration and decision-making.
Web scrapers can be categorized based on various criteria, such as their build type, deployment method, and installation location. These categories include self-built or pre-built scrapers, browser extensions or software applications, and cloud-based or local installations.
For those with advanced programming skills, building a web scraper from scratch is an option. This approach allows for complete customization and control over the scraper’s functionality. However, creating a feature-rich scraper requires a significant amount of coding expertise.
Alternatively, pre-built web scrapers are readily available for download and use. These scrapers often come with various advanced features that can be easily customized to suit specific needs, making them a more convenient choice for those with limited programming knowledge.
When it comes to deployment, web scrapers can be divided into browser extensions and standalone software applications. Browser extension scrapers are easily integrated into web browsers, making them simple to use. However, their functionality is limited to the browser capabilities, restricting the inclusion of advanced features.
On the other hand, software web scrapers are separate applications that can be installed directly on a computer. Although they may be more complex than browser extensions, software scrapers offer a wider range of advanced features that are not constrained by browser limitations.
Another important consideration is the location where the web scraper runs. Cloud-based web scrapers operate on remote servers, typically provided by the company offering the scraper. This setup allows users to offload the resource-intensive task of web scraping to the cloud, freeing up their local computer for other tasks.
In contrast, local web scrapers run directly on the user’s computer, utilizing its CPU and RAM. While this approach provides more control over the scraping process, it can lead to slower computer performance, especially if the scraper demands significant resources.
In summary, web scrapers can be classified based on their build type (self-built or pre-built), deployment method (browser extension or software application), and installation location (cloud-based or local). Each category has advantages and disadvantages, and the choice ultimately depends on the user’s technical expertise, desired features, and available resources. By understanding these distinctions, users can select the most appropriate web scraper for their specific needs, ensuring efficient and effective data extraction from websites.

Check Out Our Video to Learn More About Scraping Websites Like Yelp!
We can do web scraping with Python.
Scrapy is a fast high-level web crawling and web scraping framework used to crawl websites and extract structured data from their pages. It can be used for a wide range of purposes, from data mining to monitoring and automated testing. It is developed & maintained by Scrapinghub and many other contributors.
Scrapy is best out of the two because in it we have to focus mostly on parsing the webpage HTML structure and not on sending requests and getting HTML content from the response, in Scrapy that part is done by Scrapy we have to only mention the website URL.
A Scrapy project can also be hosted on Scrapinghub, we can set a schedule for when to run a scraper.
Selenium Python bindings provide a simple API to write functional/acceptance tests using Selenium WebDriver. Through Selenium Python API you can access all functionalities of Selenium WebDriver in an intuitive way.
Selenium is used to scrape websites that load content dynamically like Facebook, Twitter, etc. or if we have to perform a click or scroll page action to log in or signup to get to the page that has to be scrapped.
Selenium can be used with Scrapy and Beautiful Soup after the site has loaded the dynamically generated content we can get access to the HTML of that site through selenium and pass it to Scrapy or beautiful soup and perform the same operations.
Sandeep is a highly experienced Python Developer with 15+ years of work experience developing heterogeneous systems in the IT sector. He is an expert in building integrated web applications using Java and Python. With a background in data analytics. Sandeep has a knack for translating complex datasets into meaningful insights, and his passion lies in interpreting the data and providing valuable predictions with a good eye for detail.
Get Free ConsultationStep 1 => Since we are only fetching restaurant reviews in San Francisco, the scraping URL will redirect us to the page below.
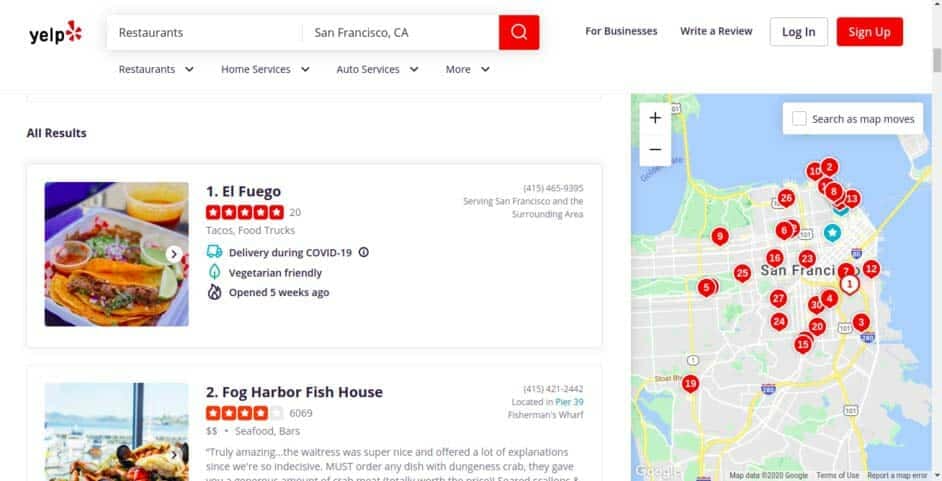
Step 2 => We will now create a Scrapy project with the command below.
Scrapy startproject restaurant_reviews Scrapy project structure
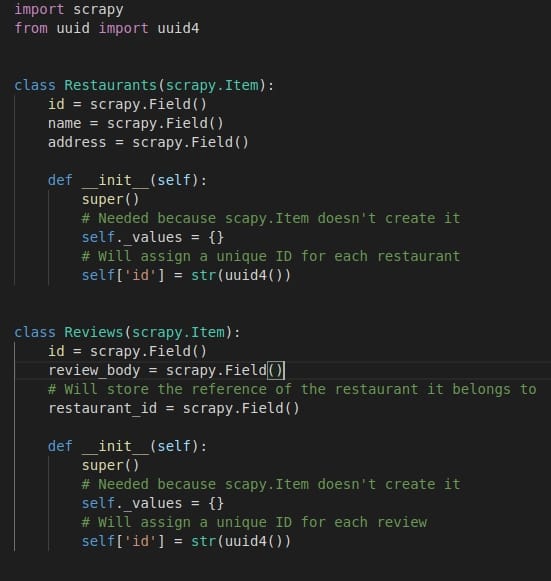
Step 3 => Now we will create 2 items (Restaurant and Review) in items.py to store and output the extracted data in a structured format.
Step 4 => Now we will create a custom pipeline, in Scrapy to output data in 2 separate CSV files (Restaurants.csv & Reviews.csv). After creating the custom pipeline we will add it in ITEM_PIPELINES of Scrapy settings.py file.
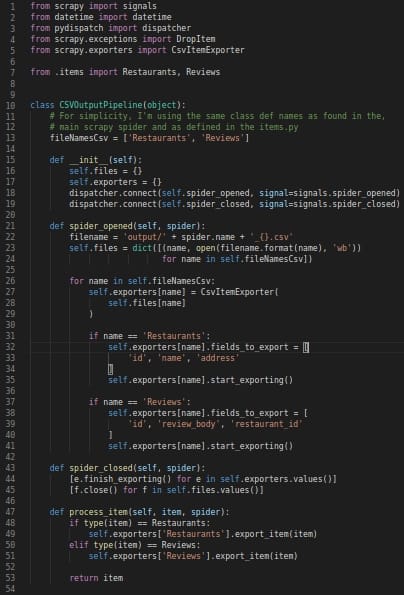
settings.py

The company is a B2B collaborative platform. To build the marketplace the company is required to consistently find suppliers as well as keep a tab on new and existing suppliers. We helped scrape supplier information from 500+ websites. Scraping is automated for most websites and the customer gets instant alerts as soon as there is a change in supplier status or a new supplier is added.
The solution helped the company grow its marketplace by piggybacking on its competitors.
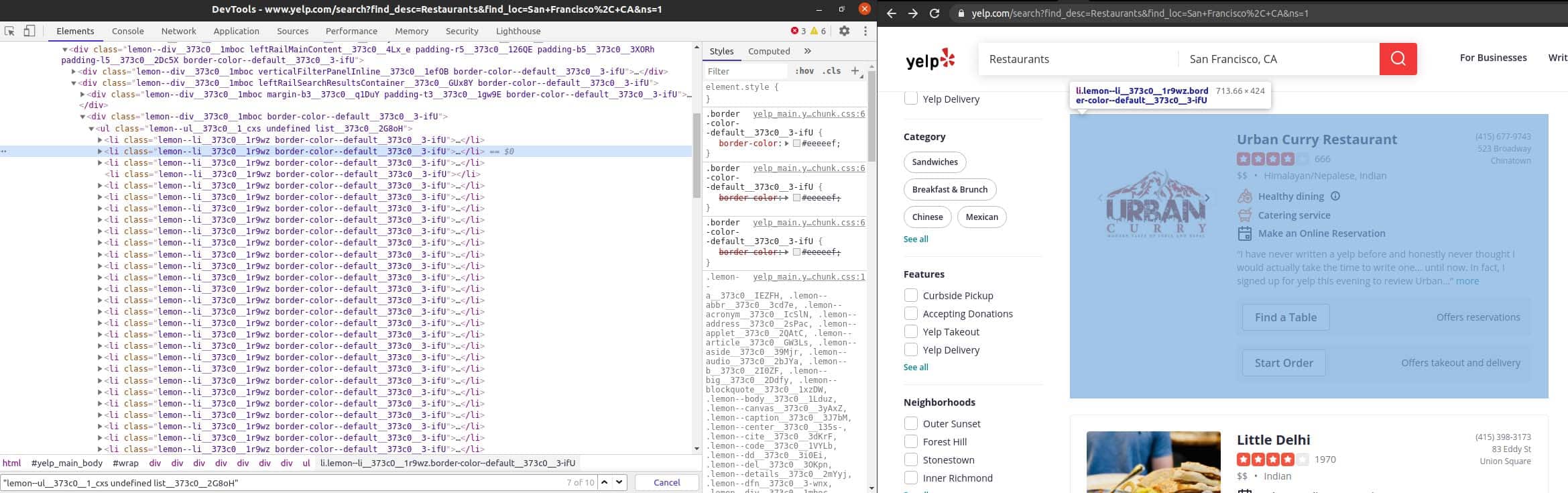

1. Restaurants.csv
Here we can see all the restaurants fetched.
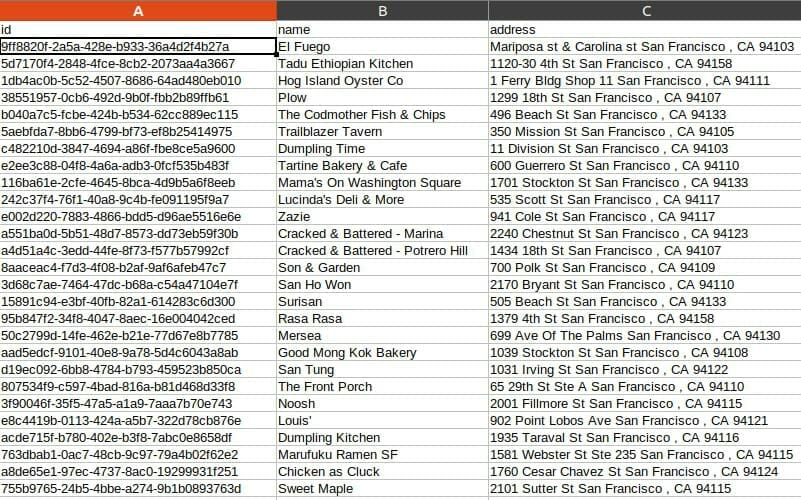
2. Reviews.csv
Here we can see the reviews with their restaurant references.
When you appoint data scraping experts from Mindbowser, we dedicatedly provide end-to-end support to accomplish your organizational objectives quickly.


The above example shows us the web scraping process and how with the help of some tools, we can extract information from a website for several purposes. It only shows a basic use case of Scrapy, it can do much more.
We can do a lot of things with the output of the above example, like:
We can also extract reviews from other review sites.

We worked with Mindbowser on a design sprint, and their team did an awesome job. They really helped us shape the look and feel of our web app and gave us a clean, thoughtful design that our build team could...

The team at Mindbowser was highly professional, patient, and collaborative throughout our engagement. They struck the right balance between offering guidance and taking direction, which made the development process smooth. Although our project wasn’t related to healthcare, we clearly benefited...

Founder, Texas Ranch Security
Mindbowser played a crucial role in helping us bring everything together into a unified, cohesive product. Their commitment to industry-standard coding practices made an enormous difference, allowing developers to seamlessly transition in and out of the project without any confusion....

CEO, MarketsAI
I'm thrilled to be partnering with Mindbowser on our journey with TravelRite. The collaboration has been exceptional, and I’m truly grateful for the dedication and expertise the team has brought to the development process. Their commitment to our mission is...

Founder & CEO, TravelRite
The Mindbowser team's professionalism consistently impressed me. Their commitment to quality shone through in every aspect of the project. They truly went the extra mile, ensuring they understood our needs perfectly and were always willing to invest the time to...

CTO, New Day Therapeutics
I collaborated with Mindbowser for several years on a complex SaaS platform project. They took over a partially completed project and successfully transformed it into a fully functional and robust platform. Throughout the entire process, the quality of their work...

President, E.B. Carlson
Mindbowser and team are professional, talented and very responsive. They got us through a challenging situation with our IOT product successfully. They will be our go to dev team going forward.

Founder, Cascada
Amazing team to work with. Very responsive and very skilled in both front and backend engineering. Looking forward to our next project together.

Co-Founder, Emerge
The team is great to work with. Very professional, on task, and efficient.

Founder, PeriopMD
I can not express enough how pleased we are with the whole team. From the first call and meeting, they took our vision and ran with it. Communication was easy and everyone was flexible to our schedule. I’m excited to...

Founder, Seeke
We had very close go live timeline and Mindbowser team got us live a month before.

CEO, BuyNow WorldWide
If you want a team of great developers, I recommend them for the next project.

Founder, Teach Reach
Mindbowser built both iOS and Android apps for Mindworks, that have stood the test of time. 5 years later they still function quite beautifully. Their team always met their objectives and I'm very happy with the end result. Thank you!

Founder, Mindworks
Mindbowser has delivered a much better quality product than our previous tech vendors. Our product is stable and passed Well Architected Framework Review from AWS.

CEO, PurpleAnt
I am happy to share that we got USD 10k in cloud credits courtesy of our friends at Mindbowser. Thank you Pravin and Ayush, this means a lot to us.

CTO, Shortlist
Mindbowser is one of the reasons that our app is successful. These guys have been a great team.

Founder & CEO, MangoMirror
Kudos for all your hard work and diligence on the Telehealth platform project. You made it possible.

CEO, ThriveHealth
Mindbowser helped us build an awesome iOS app to bring balance to people’s lives.

CEO, SMILINGMIND
They were a very responsive team! Extremely easy to communicate and work with!

Founder & CEO, TotTech
We’ve had very little-to-no hiccups at all—it’s been a really pleasurable experience.

Co-Founder, TEAM8s
Mindbowser was very helpful with explaining the development process and started quickly on the project.

Executive Director of Product Development, Innovation Lab
The greatest benefit we got from Mindbowser is the expertise. Their team has developed apps in all different industries with all types of social proofs.

Co-Founder, Vesica
Mindbowser is professional, efficient and thorough.

Consultant, XPRIZE
Very committed, they create beautiful apps and are very benevolent. They have brilliant Ideas.

Founder, S.T.A.R.S of Wellness
Mindbowser was great; they listened to us a lot and helped us hone in on the actual idea of the app. They had put together fantastic wireframes for us.

Co-Founder, Flat Earth
Ayush was responsive and paired me with the best team member possible, to complete my complex vision and project. Could not be happier.

Founder, Child Life On Call
The team from Mindbowser stayed on task, asked the right questions, and completed the required tasks in a timely fashion! Strong work team!

CEO, SDOH2Health LLC
Mindbowser was easy to work with and hit the ground running, immediately feeling like part of our team.

CEO, Stealth Startup
Mindbowser was an excellent partner in developing my fitness app. They were patient, attentive, & understood my business needs. The end product exceeded my expectations. Thrilled to share it globally.

Owner, Phalanx
Mindbowser's expertise in tech, process & mobile development made them our choice for our app. The team was dedicated to the process & delivered high-quality features on time. They also gave valuable industry advice. Highly recommend them for app development...

Co-Founder, Fox&Fork



