



















 BLOGS
BLOGS  NEWSROOM
NEWSROOM  CASE STUDIES
CASE STUDIES  WEBINARS
WEBINARS  PODCASTS
PODCASTS  ASSET HUB
ASSET HUB  EVENT CALENDAR
EVENT CALENDAR 





























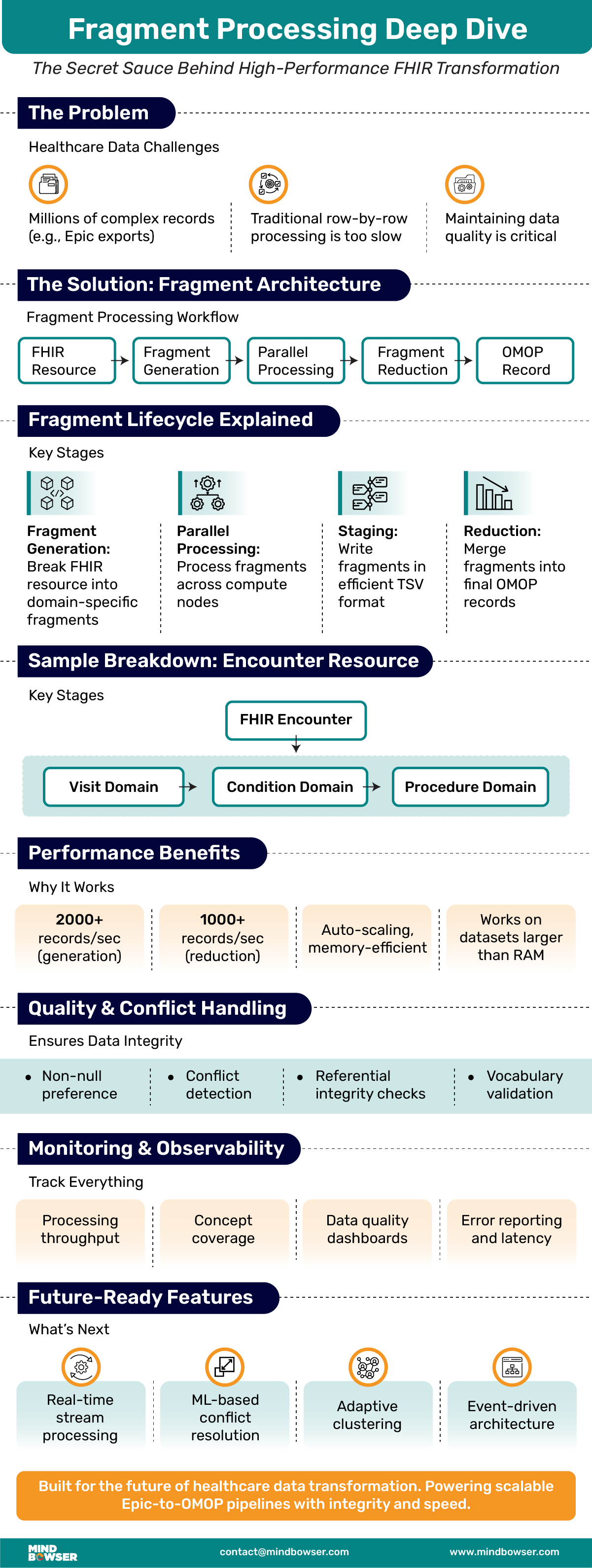
Bridging the gap between real-world clinical data and research-ready datasets, fragment processing plays a pivotal role in converting FHIR resources into the OMOP Common Data Model (CDM). At Mindbowser, we’ve architected a robust transformation pipeline that dissects massive FHIR exports—like patient records, procedures, observations, and medications—into structured fragments.
These fragments are enriched with standardized terminology, deduplicated, and efficiently bulk‑loaded into OMOP tables. This “fragment‑processing” approach solves key challenges of scale, data integrity, and performance, enabling healthcare organizations to transform raw EHR data into analytics-ready repositories with speed, accuracy, and compliance.
The Performance Challenge
Healthcare systems often struggle with fragmented data across EHR systems, making efficient, high-quality transformation of millions of complex medical records a major challenge. Traditional row-by-row processing becomes a bottleneck when dealing with Epic’s bulk exports containing hundreds of thousands of patient encounters.
The answer lies in fragment-based processing—a sophisticated approach that breaks complex transformations into parallelizable components.
Understanding Fragment Architecture
Fragment processing operates on a simple but powerful principle: instead of trying to transform complete FHIR resources into final OMOP records in a single step, break the process into manageable pieces (fragments) that can be processed independently and then intelligently assembled.
The Fragment Lifecycle
- Fragment Generation: FHIR resources are decomposed into target-table-specific fragments
- Parallel Processing: Multiple fragments are processed simultaneously across compute nodes
- Staging: Fragments are written to disk in an efficient tab-separated format
- Reduction: Fragments are consolidated, conflicts resolved, and final records generated
This approach enables massive parallelization while maintaining data integrity and clinical context.
Stage 3: Fragment Generation Deep Dive
The fragment generation stage is where the magic happens. A single FHIR Encounter resource might generate multiple fragments destined for different OMOP tables:
Example: Complex Encounter Processing
Input FHIR Encounter:
{
"resourceType": "Encounter",
"id": "encounter-12345",
"type": [{
"coding": [
{"code": "185349003", "system": "snomed", "display": "Checkup"},
{"code": "38341003", "system": "snomed", "display": "Hypertension"},
{"code": "71620000", "system": "snomed", "display": "Dialysis"}
]
}],
"subject": {"reference": "Patient/patient-67890"},
"period": {
"start": "2023-12-15T10:00:00Z",
"end": "2023-12-15T11:00:00Z"
}
}Generated Fragments:
🔹 Fragment 1 (Visit Domain):
visit_occurrence encounter-12345 patient-67890 4024660 2023-12-15 2023-12-15T10:00:00 2023-12-15 2023-12-15T11:00:00 44818518 …
Fragment 2 (Condition Domain):
condition_occurrence encounter-12345 patient-67890 320128 2023-12-15 2023-12-15T10:00:00 2023-12-15 2023-12-15T11:00:00 32817 …
Fragment 3 (Procedure Domain):
procedure_occurrence encounter-12345 patient-67890 4301351 2023-12-15 2023-12-15T10:00:00 2023-12-15 2023-12-15T11:00:00 32817 …
Fragment Structure Design
Each fragment follows a consistent structure:
- 🔸 Table Name Prefix: Identifies the target OMOP table
- 🔸 Primary Key: Enables duplicate detection and merging
- 🔸 Tab-Separated Values: Optimized for bulk loading performance
- 🔸 Complete Row Data: All required OMOP CDM columns
This structure enables efficient downstream processing while maintaining full data integrity.
Parallel Processing Benefits
Parallel processing helps overcome the challenges of fragmented data by enabling the simultaneous transformation of independently structured FHIR resources.
Fragment generation enables massive parallelization:
Compute Distribution
- 🔸 Multiple FHIR files processed simultaneously
- 🔸 Independent fragment streams avoid processing bottlenecks
- 🔸 Resource-specific processing optimizes for data characteristics
- 🔸 Auto-scaling clusters adjust to processing demands
Memory Optimization
- 🔸 Streaming processing avoids loading entire datasets
- 🔸 Fragment caching optimizes repeated access patterns
- 🔸 Garbage collection minimizes memory pressure
- 🔸 Disk spilling handles datasets larger than memory
Ready to Optimize Your FHIR-to-OMOP Pipeline?
Stage 4: Fragment Reduction Mastery
The fragment reducer is where individual fragments are consolidated into final OMOP tables. This stage handles the complex logic of merging related data while resolving conflicts and maintaining referential integrity.
The reduction stage consolidates fragmented data generated across different domains, resolving conflicts and creating unified OMOP-compliant records.
🔹 The Reduction Algorithm
- Fragment Grouping: Group fragments by target OMOP table
- Primary Key Sorting: Sort fragments by primary key for efficient processing
- Conflict Resolution: Merge fragments with identical primary keys
- Quality Validation: Ensure final records meet OMOP CDM requirements
- Bulk Loading: Generate final tab-separated files for database import
🔹 Conflict Resolution Logic
When multiple fragments contribute to the same OMOP record, intelligent conflict resolution ensures data quality:
🔸 Non-Null Preference
Fragment A: person_id=123, gender_concept_id=8507, birth_year=NULL
Fragment B: person_id=123, gender_concept_id=NULL, birth_year=1975
Result: person_id=123, gender_concept_id=8507, birth_year=1975
🔸 Conflict Detection
Fragment A: person_id=123, gender_concept_id=8507
Fragment B: person_id=123, gender_concept_id=8532
Result: ERROR – Gender conflict for person 123
🔸 Source Preservation
All fragments maintain source_value fields for traceability:
condition_source_value=”38341003″ // Original SNOMED code
Performance Characteristics
Fragment processing delivers exceptional performance metrics:
🔹 Processing Speed
- 🔸 2000+ records/second during fragment generation
- 🔸 1000+ records/second during fragment reduction
- 🔸 Linear scaling with additional compute nodes
- 🔸 Burst processing handles monthly bulk exports efficiently
🔹 Resource Efficiency
- Memory-optimized: Processes datasets larger than available RAM
- Disk-efficient: TSV format minimizes storage requirements
- Network-optimized: Minimizes data movement between nodes
- Cost-effective: Auto-scaling reduces idle compute costs
Quality Assurance Framework
Fragment processing includes comprehensive quality controls:
🔹 Fragment Validation
- 🔸 Schema compliance: Each fragment matches target table structure
- 🔸 Data type validation: Ensures numeric, date, and text field accuracy
- 🔸 Required field checking: Validates presence of mandatory OMOP fields
- 🔸 Concept validation: Confirms all concept_ids exist in vocabularies
🔹 Reduction Quality Checks
- 🔸 Completeness monitoring: Tracks record counts through each stage
- 🔸 Conflict reporting: Identifies and reports data inconsistencies
- 🔸 Referential integrity: Validates foreign key relationships
- 🔸 Statistical validation: Compares input/output record distributions
Monitoring and Observability
Production fragment processing requires comprehensive monitoring:
🔹 Real-Time Metrics
- 🔸 Processing throughput: Records per second by stage
- 🔸 Error rates: Fragment validation failures
- 🔸 Resource utilization: CPU, memory, and disk usage
- 🔸 Queue depths: Processing backlogs by resource type
🔹 Quality Dashboards
- 🔸 Data completeness: Percentage of required fields populated
- 🔸 Concept coverage: Vocabulary mapping success rates
- 🔸 Processing latency: End-to-end pipeline timing
- 🔸 Cost tracking: Compute resource consumption
Troubleshooting Common Issues
Fragment processing systems require proactive issue management:
🔹 Performance Bottlenecks
- 🔸 Memory pressure: Optimize fragment size and caching
- 🔸 Disk I/O limits: Distribute processing across storage systems
- 🔸 Network bandwidth: Minimize cross-node data movement
- 🔸 CPU saturation: Scale compute clusters appropriately
🔹 Data Quality Issues
- 🔸 Unmapped concepts: Expand vocabulary coverage
- 🔸 Duplicate records: Enhance primary key generation logic
- 🔸 Missing references: Improve foreign key resolution
- 🔸 Schema violations: Update fragment validation rules
Advanced Optimization Techniques
Production implementations benefit from advanced optimizations:
🔹 Intelligent Caching
- 🔸 Vocabulary caching: Pre-load concept mappings for speed
- 🔸 Fragment templating: Reuse common record structures
- 🔸 Checkpoint optimization: Enable fast recovery from failures
- 🔸 Result caching: Avoid reprocessing unchanged data
🔹 Adaptive Processing
- 🔸 Dynamic clustering: Adjust resources based on workload
- 🔸 Intelligent partitioning: Optimize data distribution
- 🔸 Priority queuing: Process critical resources first
- 🔸 Load balancing: Distribute work across available nodes
Future Enhancements
Fragment processing continues to evolve:
🔹 Real-Time Processing
- 🔸 Stream processing: Handle real-time FHIR updates
- 🔸 Incremental reduction: Update records without full reprocessing
- 🔸 Change data capture: Track modifications to source data
- 🔸 Event-driven architecture: Trigger processing based on data changes
🔹 Machine Learning Integration
- 🔸 Intelligent conflict resolution: Learn optimal merge strategies
- 🔸 Quality prediction: Identify potential data issues proactively
- 🔸 Performance optimization: Automatically tune processing parameters
- 🔸 Anomaly detection: Flag unusual data patterns for review
Fragment processing represents a fundamental advancement in healthcare data transformation, enabling the scale and performance required for modern Epic-to-OMOP pipelines while maintaining the data quality essential for research excellence.

By turning fragmented data from bulk FHIR exports into high-integrity OMOP records, fragment processing lays the foundation for scalable and trustworthy real-world evidence generation.
Fragment processing techniques build upon distributed computing principles adapted for healthcare data, with recognition to Carl Anderson and the FHIR Analytics community for pioneering scalable approaches to clinical data transformation.
Fragment processing is a technique that breaks down complex FHIR resources into smaller, manageable units (fragments), which are independently processed and later merged into OMOP-compliant records. This enables parallelization and high-speed transformation.
Epic bulk exports can contain millions of records. Traditional sequential processing becomes a bottleneck at this scale. Fragment processing allows simultaneous handling of different parts of the data, achieving speeds of over 2000 records/second.
It includes built-in validation checks at each stage—schema compliance, concept validation, conflict resolution, and referential integrity. Errors and inconsistencies are logged and managed intelligently during reduction.


