



















 BLOGS
BLOGS  NEWSROOM
NEWSROOM  CASE STUDIES
CASE STUDIES  WEBINARS
WEBINARS  PODCASTS
PODCASTS  ASSET HUB
ASSET HUB  EVENT CALENDAR
EVENT CALENDAR 


























Training and running an AI model can be a tedious process. It can involve dealing with large amounts of quality data and working with complex and computationally expensive mathematical algorithms. So it makes much more sense to make use of the well-trained and tested models that are already available through ChatGPT APIs. Integrating such AI capabilities has been proven to significantly enhance user experience and speed up a lot of online processes.
The ChatGPT API is a powerful tool that leverages artificial intelligence to generate human-like text based on given prompts. This API has found applications in various fields, including customer service, content creation, coding, and more. Understanding the key parameters of the ChatGPT API and their mathematical significance can greatly enhance the quality and relevance of the generated text. Let us delve deeper into some of the important parameters that help us control the responses from the OpenAI models.
Model
- Specifies the version of the AI model to use like gpt-4, gpt-3.5-turbo etc.
- OpenAI periodically updates its models, each offering improvements in understanding and generating text.
- The choice of model affects the quality of responses, with newer models generally providing more accurate and contextually relevant completions.
Messages (Prompt)
🔸 This is the input list of messages to which the model responds.
🔸 The prompt sets the context and specifies the task for the ChatGPT API. It can be seen as the initial condition for the generative process, where the model applies conditional probability to generate the next sequence of words.
🔸 Its value can be a list of objects describing:
- Role – It is used to guide the model’s response towards a specific conversational role or persona. It influences the tone, style, and content of the generated text to better align with the desired conversational context.
- Content – Contains a wide range of textual content that serves as input to the ChatGPT API. It can be questions, commands, instructions, statements, etc. Some models like gpt-4-vision-preview also accept image input URLs.
- Name – An optional name for the participant. Provides the model information to differentiate between participants of the same role.
🔸 It’s important to provide clear and specific instructions or content that guides the ChatGPT API’s behavior and helps it generate relevant and accurate responses. Experimenting with different types of content and instructions can help achieve the desired results and tailor the model’s responses to our specific needs and preferences.
🔸 In the case of chat applications, to ensure contextual awareness in the response of the model, it is necessary to also include the conversation history of a chat session.
Tokens
🔸 Tokenization is one of the primitive steps in any NLP (Natural Language Processing) pipeline where an input text is broken down into smaller units before it gets processed by a language model.
🔸 A token is a group of typically 1 to 4 characters that do not necessarily form a meaningful word and are derived from common character combinations that are observed across languages.
🔸 ChatGPT API’s vast database stores distinct tokens, each assigned with a unique identifier or token ID based on its frequency in the training data. The higher the frequency of a token in the training data, the lower will be its ID value.
🔸 Check out OpenAI’s tokenizer tool to understand how a piece of text might be tokenized using different algorithms.
🔸 Open AI charges its ChatGPT API users based on the total number of tokens exchanged in a request i.e., the sum of tokens in the request/prompt and the model’s response.
🔸 The parameter “max_tokens” controls the maximum number of tokens that can be exchanged in a request and thus modulates the cost per request and the concision of a model’s response.
🔸As AI-generated content becomes more widespread, it’s also important to evaluate its originality and authenticity, using an AI detector can help identify whether text appears machine-generated and ensure higher content quality.
Related read: Large Language Models: Complete Guide For 2024
Temperature
🔸 Temperature-based sampling algorithms use the softmax function to generate a probability distribution for a set of predicted tokens and the “temperature” parameter is used to adjust the sampling process by scaling the logits (log probabilities).
🔸 The temperature value scales the logits before applying softmax during text generation, affecting the probability distribution of the next word. A higher temperature value results in a flatter probability distribution, making it more likely for the model to select less probable tokens, resulting in more creative output.
Softmax(zi) = exp(zi) / jexp(zj)
Temperature Scaling =>
Softmax(zi) = exp(zi / Temperature) / jexp(zj / Temperature)
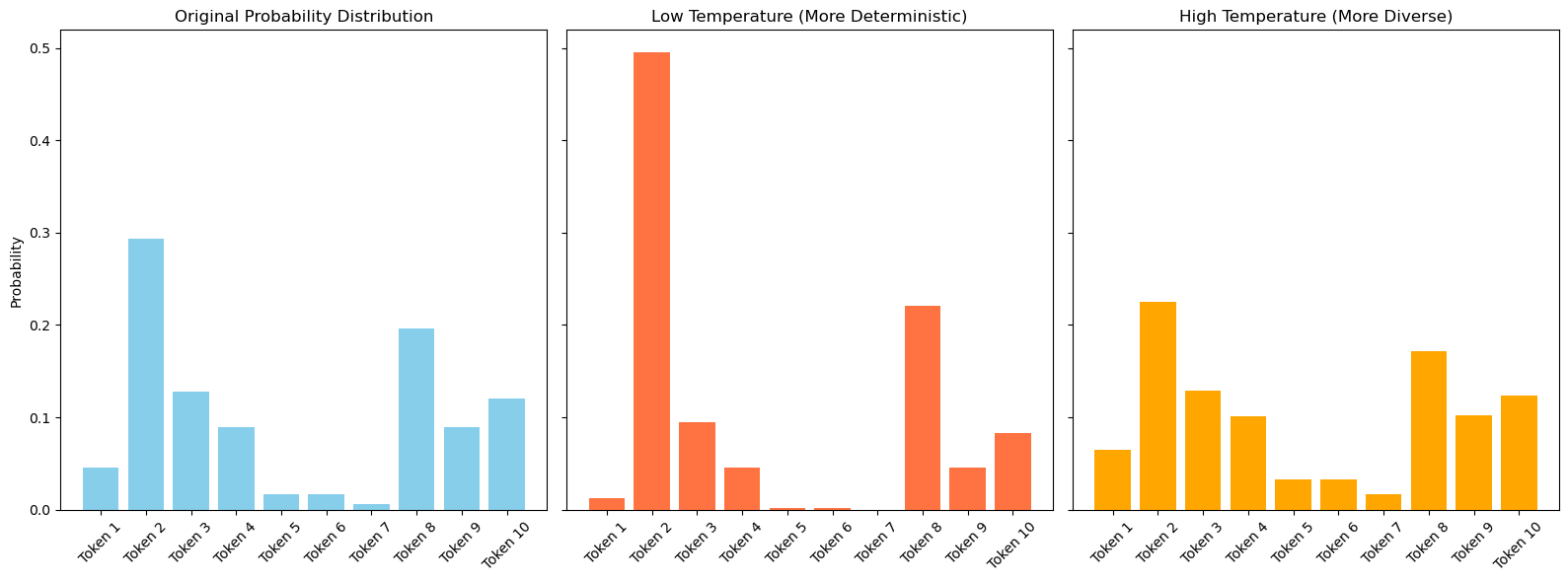
🔸 At a low temperature (e.g., 0.2), the model’s responses are likely to be conservative and similar across runs. As we increase the temperature to a high value (e.g., 0.9), the responses become more diverse but may also include more surprising or less predictable elements.
🔸 Typical use cases for different values of temperature:
- Low Temperature (Close to 0): Factual content, Code generation, Formal communications, etc.
- Medium Temperature (0.5-0.8): General content, Educational explanations, Customer support, etc.
- High Temperature (1 and above): Creative writing, Brainstorming, etc.
Top-p
🔸 The “top_p” parameter value determines the threshold for the sampling algorithm which would consider the most probable tokens that collectively make up the probability mass not exceeding the threshold value.
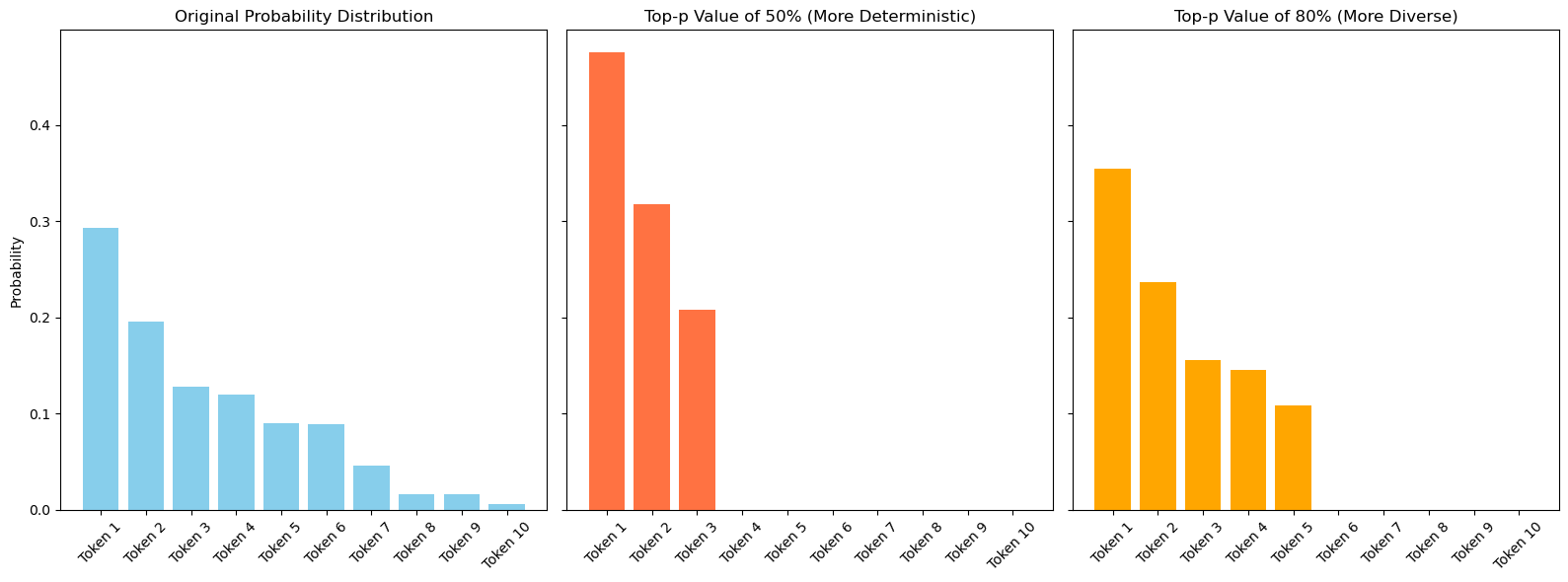
🔸 The top-p sampling strategy truncates the cumulative probability distribution, allowing only a subset of tokens to be considered for selection based on their cumulative probability. The resulting probabilities of the subset are then re-normalized so that they sum up to 1.
🔸 Applying a top-p value of 80% modifies the original distribution by considering only the top tokens whose cumulative probability adds up to 80%. This filters out the least likely tokens while retaining a significant portion of the distribution, allowing for diversity in the generated text but with a focus on more probable tokens.
🔸 A top-p value of 50% results in a more concentrated selection of tokens, with only the most probable tokens being considered. This significantly reduces the diversity of the output but increases the likelihood that the generated text will be coherent and on-topic, as it relies on the most probable tokens.
🔸 Both the parameters Temperature and Top-p can be used to control the diversity of the model responses. Temperature does so by affecting all tokens equally across the distribution whereas, Top-p does so by dynamically adjusting the range of considered tokens based on the desired cumulative probability.
Optimize Your Text Generation with ChatGPT API. Elevate Your Content to New Heights. Explore Now!
Frequency and Presence Penalties
🔸 The Frequency penalty parameter penalizes a token or a sequence of tokens based on how often it has already been sampled, whereas the Presence penalty parameter penalizes a token or a sequence of tokens based on whether it has already been sampled at least once.
🔸 They penalize by directly modifying the logits (un-normalized log probabilities) with an additive contribution as shown below.
mu[j] -> mu[j] - c[j] * alpha_frequency - float(c[j] > 0) * alpha_presence
Where,
- mu[j] is the logits of the j-th token
- c[j] is how often that token was sampled before the current position
- alpha_frequency is the frequency penalty coefficient
- alpha_presence is the presence penalty coefficient
🔸 Penalty values can be between -2.0 to 2.0 and a positive value can be used to decrease the likelihood of repetition. Note that a high coefficient value close to 2 can strongly suppress repetition but can also degrade the quality of samples.
Logarithm of Probability
🔸 The “logprobs” parameter specifies the number of most likely tokens and their respective log probabilities to be returned in the ChatGPT API’s response for every token sampled in the completion.
🔸 The log probability value of a token is the natural logarithm of its probability value and the probabilities that are very close to zero are very negative in their logarithmic form.
🔸 Probability values in their raw form can be very small and difficult to work with, but their logarithmic values can be more manageable and computationally efficient.
🔸 Log probabilities can provide analytical insight into the capabilities of a language model based on which, an additional level of fine control and flexibility can be attained in generating optimized responses.
Logit Bias
🔸 Logits are the unnormalized numerical values produced by the model’s last linear layer that represent the model’s confidence over each possible class in a classification task. The logits are often passed through an activation function (such as softmax) to produce a probability distribution over the classes.
🔸 The “logit_bias” parameter accepts a JSON object that maps token IDs to bias values (-100 to 100). The specified bias values are added to the logits generated by the model for the respective tokens, thus affecting their likelihood of getting sampled.
🔸 The parameter can be used to influence a model’s preference for generating or avoiding a particular set of tokens in its response. For example, a collection of tokens related to a desired topic can be assigned with positive bias values to encourage the language model to generate text related to the topic more frequently.
Tools
🔸 A list of functions intended to be called upon receiving a response from the model.
🔸 The model returns a JSON object containing all the appropriate values for the arguments of a function.
🔸 They can be used to customize the post-processing of the ChatGPT API’s responses to meet specific requirements, enhance the quality of the generated text, and ensure that the output is suitable for the intended application or audience.
Stream
🔸 It provides flexibility in controlling the behavior of the ChatGPT API response, allowing us to choose between real-time streaming of the generated tokens or receiving the complete response as a single block of text based on our specific requirements and use case.
🔸 Models trained by the ChatGPT API can take a considerable amount of time to generate responses, and real-time streaming can be beneficial for applications that require immediate feedback or continuous interaction with the model during the generation process.
Conclusion
Understanding and effectively utilizing the parameters of the ChatGPT API can significantly enhance the quality and relevance of the generated text. By carefully adjusting parameters like temperature, top_p, and max_tokens, users can tailor the model’s output to meet specific needs, balancing creativity, diversity, and coherence. For much more fine-grained control, parameters like frequency and presence penalties and logit bias can be used by influencing the likelihood of specific tokens.

